
AI+HUMAN Translation Process Explained for Regulated Industries
- 3 hours ago
- 9 min read

AI+HUMAN hybrid translation is defined as a structured, compliance-driven workflow that combines governed AI generation with certified human post-editing to produce audit-ready technical documentation. The industry standard term for the human review stage is post-editing of machine translation output, formalized under ISO 18587. For regulated industries, this integrated process is not optional. A single mistranslation in a medical device instruction, a legal contract, or a defense specification can trigger regulatory non-conformance, product recalls, or liability. The AI+HUMAN translation process delivers the speed of AI generation with the accountability of subject-matter expert review, aligned to ISO 17100 and ISO 18587 throughout.
What are the key stages of the AI+HUMAN hybrid translation process?
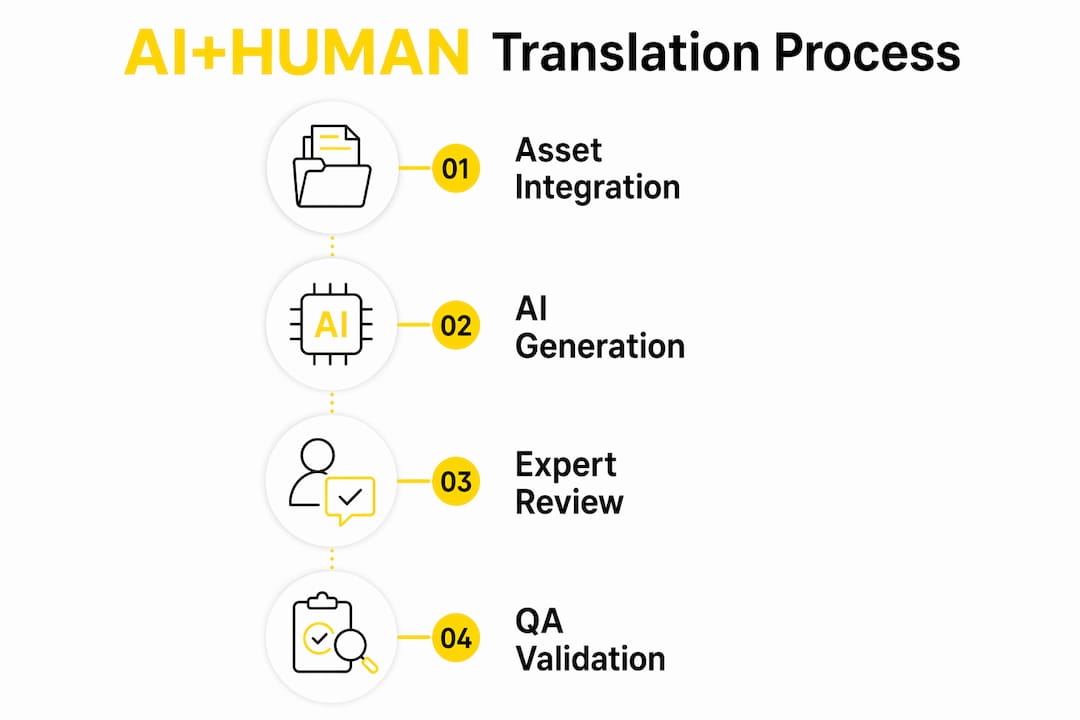
The four-stage process for AI+HUMAN hybrid translation covers asset preparation, governed AI generation, expert post-editing, and formal QA validation. Each stage has a defined input, output, and compliance checkpoint. Skipping or compressing any stage introduces audit risk.
Stage 1: Asset integration
Asset integration is the first and most consequential stage. The workflow ingests client Translation Memories ™ and Term Bases (TB) before any AI generation begins. TMs carry previously approved translations that the AI must reuse verbatim for consistency. TBs enforce approved terminology across every segment, preventing the AI from substituting synonyms that may carry different regulatory meaning.

Stage 2: LLM-based AI generation
The AI generation stage uses a proprietary LLM-based system constrained by the client’s terminology and style guidance loaded in Stage 1. This is not legacy Machine Translation (MT), which produces literal output with weak context handling and a high rate of meaning errors in safety-critical text. It is also distinct from broadly available Neural Machine Translation (NMT) engines, which carry inconsistent terminology control and governance limitations for regulated documentation. The LLM-based approach handles document-level context and follows explicit instructions, producing output that is far closer to the target register before any human review begins.
Stage 3: Certified subject-matter expert review
Human post-editing is indispensable for legal, medical, financial, and defense content. A certified subject-matter expert reviews every segment for technical accuracy, regulatory compliance, and contextual nuance. This is not a light proofread. The reviewer checks that negations are preserved, that safety warnings carry the correct force, and that domain-specific terms match the approved TB exactly.
Stage 4: Formal QA validation
QA validation closes the workflow. The process aligns to ISO 17100 and ISO 18587 and, where the content requires it, to sector-specific frameworks such as MDR for medical devices. QA covers error categorization, segment-level sign-off, and documentation of the review chain for audit purposes.
Pro Tip: Build your TM and TB before the first project, not during it. Retroactively applying terminology corrections across a completed translation is significantly more costly than front-loading asset preparation.
How does glossary management and prompt engineering improve AI translation quality?
Glossary extraction and control is the most critical prerequisite step in any AI+HUMAN workflow. Experts confirm that skipping glossary extraction risks tone flattening and inconsistent terminology, which can invalidate technical documentation in regulatory audits. A glossary is not a dictionary. It is a controlled list of approved source terms mapped to approved target terms, with usage context and regulatory status attached to each entry.
Prompt engineering extends glossary control into the AI generation layer. The technique involves injecting approved terms, prohibited synonyms, style rules, and document-level context directly into the AI prompt before generation begins. Locking terminology into AI prompts reduces silent edits by over 50% compared to standard zero-shot prompting. Silent edits are substitutions the AI makes without flagging them as changes, often replacing a precise regulatory term with a near-synonym that carries a different legal or clinical meaning.
Key practices for glossary and prompt management include:
Extract glossaries from existing approved documentation, not from general reference sources.
Map every source term to exactly one approved target term per language pair.
Flag terms with regulatory status (e.g., INN drug names, ISO-defined safety signal words) as locked in the prompt.
Include negative examples in prompts to block known substitution errors from prior runs.
Version-control your prompt library alongside your TM and TB.
Semantic drift is the gradual divergence of translated meaning from the source across a long document or a series of related documents. Controlled glossaries and structured prompts are the primary controls against drift. Without them, an AI system will produce internally consistent output that is nonetheless inconsistent with the approved terminology corpus.
Pro Tip: Run a terminology enforcement audit on your existing TM before each new project. Outdated approved terms are a leading cause of QA failures in regulated translation workflows.
What are the compliance-critical QA methods in AI+HUMAN translation workflows?
Formal QA in a regulated AI+HUMAN workflow goes beyond spell-checking and fluency review. Four specific techniques address the compliance risks that AI generation introduces.
Ambiguity filtering flags high-risk source strings before translation begins. Ambiguity filters and modular AI prompt sequencing identify segments where the source text is structurally ambiguous, where a term has multiple valid translations, or where the AI is likely to produce a statistically plausible but contextually incorrect output. Filtering these strings for human pre-review prevents incorrect translations from entering the TM as false positives.
Back-translation diff is a verification technique that produces a literal retranslation of the target output back into the source language. Back-translation diff checks detect semantic drift by comparing the retranslated text against the original source segment by segment. Any divergence above a set threshold triggers human review of that segment. This technique is particularly valuable for safety warnings, dosage instructions, and legal obligation clauses.
Quality estimation models evaluate AI output quality at the segment level before human review begins. Quality estimation models guide human editing priorities, directing reviewer attention to the segments most likely to contain errors. This selective approach keeps turnaround times short without reducing accuracy on high-risk segments.
QA technique | Primary risk addressed | Compliance relevance |
Ambiguity filtering | Incorrect AI inference on unclear source text | Prevents non-conforming segments from entering TM |
Back-translation diff | Semantic drift across document | Verifies meaning fidelity for safety-critical content |
Quality estimation | Undetected AI errors in low-risk segments | Allocates human review effort to highest-risk segments |
ISO 18587 post-editing | Regulatory non-conformance in final output | Provides documented audit trail for certification bodies |
Each technique addresses a distinct failure mode. A compliant workflow uses all four in sequence, not as alternatives to each other.
What are common pitfalls in AI+HUMAN hybrid translation workflows?
Terminology inconsistency is the most common failure mode in AI+HUMAN workflows. It occurs when the TB is incomplete, outdated, or not loaded into the AI generation stage. The AI then selects terms based on statistical frequency rather than regulatory approval, producing output that passes fluency review but fails a terminology audit.
The following risks appear repeatedly in regulated translation projects:
Silent edits: The AI substitutes an approved term with a near-synonym without flagging the change. These are invisible to reviewers who do not check against the TB.
Tone flattening: The AI normalizes the register of safety warnings, reducing imperative language to advisory language. A “must not” becomes a “should not,” which carries a different compliance weight under ISO and IEC standards.
AI hallucination in technical content: The AI generates a plausible-sounding but factually incorrect specification value, unit of measure, or regulatory reference. This risk is highest in highly technical documents with dense numerical content.
Incomplete post-editing: Reviewers under time pressure accept AI output on low-confidence segments rather than correcting them. Quality estimation models exist specifically to prevent this by flagging those segments.
The mitigation for all four risks follows the same pattern. Structured translation briefs define scope, register, and prohibited substitutions before generation begins. Controlled AI prompts lock terminology and style. Certified human reviewers with domain credentials check every segment. Continuous glossary and prompt updates after each project incorporate corrections into the next run, reducing repeat errors over time.
How does AD VERBUM integrate into the AI+HUMAN translation workflow?
AD VERBUM operates a proprietary LLM-based LangOps System hosted on EU servers, with no reliance on outsourced public cloud tooling for core processing. The workflow follows the four-stage sequence described above, with AD VERBUM managing each stage under ISO 9001, ISO 17100, ISO 18587, and ISO 27001 certification.
AD VERBUM’s integration across the workflow covers:
Asset preparation: AD VERBUM ingests client TMs and TBs at project start, reconciles terminology conflicts, and flags gaps before AI generation begins.
Governed AI generation: The proprietary LangOps System applies client terminology and style guidance at the prompt level, producing output constrained by the approved TB rather than general statistical patterns.
Subject-matter expert review: AD VERBUM’s network of 3,500+ linguists includes medical professionals, engineers, and legal scholars. Reviewers are matched to the document’s domain and regulatory context.
Formal QA: QA aligns to ISO 17100 and ISO 18587, with sector-specific extensions for MDR (medical devices), HIPAA, GDPR, and AQAP 2110 (defense). Every project produces a documented review chain suitable for regulatory audit.
AD VERBUM covers 150+ languages including regional variants, and delivers at 3x to 5x the speed of traditional translation workflows. The compliant AI translation guide on the AD VERBUM site details each stage for teams preparing their first regulated localization project.
Key Takeaways
The AI+HUMAN hybrid translation process produces audit-ready technical documentation by combining governed AI generation, certified subject-matter expert review, and ISO-aligned QA in a fixed four-stage sequence.
Point | Details |
Asset integration comes first | Load TMs and TBs before AI generation to enforce approved terminology from the start. |
Prompt engineering reduces errors | Injecting glossaries into AI prompts cuts silent edits by over 50% versus zero-shot prompting. |
Human post-editing is non-negotiable | Certified subject-matter experts must review every segment in regulated content for compliance. |
QA requires four distinct techniques | Ambiguity filtering, back-translation diff, quality estimation, and ISO 18587 validation each address different failure modes. |
Continuous updates maintain quality | Glossary and prompt libraries must be updated after each project to prevent repeat errors. |
Why the brief and glossary stage determines everything downstream
After working across regulated translation projects in life sciences, defense, and legal sectors, the pattern is consistent. Teams that invest in the translation brief and glossary extraction phase produce documentation that clears audit on the first submission. Teams that skip it spend that time on rework, which costs more and creates version control problems that auditors notice.
The counterintuitive part is that the brief and glossary stage feels like overhead before the “real work” begins. It is not. Every hour spent reconciling terminology before AI generation saves three to five hours of post-editing corrections and QA cycling. I have seen projects where an incomplete TB caused the same mistranslation to propagate across 40 segments in a single document, each requiring individual correction and re-review.
The other thing practitioners underestimate is tone flattening. AI systems normalize language toward the statistical center of their training data. In regulated content, the distance between “must” and “should” is the distance between a mandatory requirement and a recommendation. That distinction is not stylistic. It is legally and regulatorily material. A post-editor who does not have domain credentials will often miss it because the sentence reads fluently. This is exactly why AD VERBUM matches reviewers to document domain rather than language pair alone.
The future of this workflow is not less human oversight. It is better-targeted human oversight, directed by quality estimation models to the segments where AI output is least reliable. The optimized AI+HUMAN workflow will look like a skilled reviewer spending focused time on genuinely difficult segments rather than scanning every line equally. That is a better use of expert capacity, and it produces more consistent audit outcomes.
— Eric Brown
AD VERBUM’s managed localization for regulated industries
AD VERBUM delivers end-to-end AI+HUMAN hybrid translation for life sciences, legal, defense, finance, and manufacturing documentation, with every project managed under ISO 17100, ISO 18587, and ISO 27001 certification.
The LangOps System handles asset integration, governed AI generation, and formal QA within a private EU-hosted infrastructure that meets GDPR, HIPAA, and MDR requirements. AD VERBUM’s localization services cover 150+ languages with subject-matter expert review on every project. For organizations that need audit-ready documentation without the compliance risk of generic AI pipelines, AD VERBUM provides a managed workflow with a documented review chain from source ingestion to final delivery. Contact AD VERBUM to discuss your regulated localization requirements and receive a project-specific process outline.
FAQ
What is the AI+HUMAN hybrid translation process?
The AI+HUMAN hybrid translation process is a four-stage workflow covering asset integration, governed AI generation, certified human post-editing, and formal QA validation aligned to ISO 17100 and ISO 18587. It produces audit-ready technical documentation for regulated industries.
How does AI+HUMAN translation differ from standard machine translation?
Legacy Machine Translation produces literal output with weak context handling and a high error rate in safety-critical text. AI+HUMAN hybrid translation uses an LLM-based system constrained by approved terminology and style guidance, followed by certified subject-matter expert review, which standard MT workflows do not include.
Why is glossary management critical in regulated translation workflows?
Glossary extraction maps every source term to a single approved target term before AI generation begins. Without it, the AI selects terms based on statistical frequency, producing output that may pass fluency review but fail a terminology audit in regulated sectors.
What QA standards apply to AI+HUMAN translation in regulated industries?
ISO 18587 governs post-editing of machine translation output, and ISO 17100 sets requirements for the full translation service workflow. Sector-specific extensions include MDR for medical devices, HIPAA for health data, and AQAP 2110 for defense documentation.
How do compliance-driven workflows reduce audit risk in technical translation?
Structured workflows with documented asset integration, controlled AI generation, expert review, and formal QA produce a traceable review chain that satisfies regulatory audit requirements. Unstructured or undocumented translation processes are the primary cause of localization-related non-conformance findings.
Recommended