
The Role of LLMs in Compliance Translation: 2026 Guide
- 3 hours ago
- 8 min read

Large Language Models (LLMs) are defined as AI systems trained on large text corpora to generate, classify, and transform language at scale. Their role in compliance translation is to produce accurate regulatory document drafts faster than traditional methods while maintaining the terminology precision that regulators require. In pharmaceuticals, finance, and life sciences, a single mistranslated term in a submission can trigger resubmission delays or regulatory penalties. Hybrid workflows combining proprietary LLM-based AI with human experts produce first drafts 3x to 5x faster than traditional translation methods while maintaining compliance. That speed advantage matters when drug approval timelines or financial filing deadlines are at stake.
How the role of LLMs in compliance translation differs from general AI translation
General-purpose LLMs struggle with compliance-specific terminology. A model trained on broad internet text does not reliably distinguish between “adverse event” and “adverse reaction” in an EMA submission context, or between “material breach” and “default” in a financial contract. Terminology drift and meaning inaccuracies remain the core risks in compliance translation using generic LLMs without domain adaptation. The consequence is not a stylistic error. It is a regulatory one.
Three translation technology tiers exist, and compliance professionals need to understand the difference between them.

Legacy Machine Translation (MT) produces literal output with weak context handling. The risk of critical meaning errors in safety-critical text is high. Neural Machine Translation (NMT), available through consumer and broadly available SaaS engines, offers better fluency but delivers inconsistent terminology control and variable handling of negation and domain nuance. Governance limitations make NMT unsuitable for regulated documentation without additional enterprise controls. Proprietary LLM-based AI, such as the system AD VERBUM operates, generates context-sensitive output with explicit instruction following and terminology governance embedded in an AI+HUMAN hybrid translation workflow.
The performance gap between specialized and general models is material. Specialized medical NMT models consistently outperform general-purpose LLMs in accuracy for life sciences translations, reducing regulatory risks from mistranslation. Errors in this category can delay drug approval by months. That is not a theoretical risk. It is a documented failure pattern.
Model type | Terminology control | Context handling | Governance fit |
Legacy MT | None | Literal only | Not suitable for regulated content |
General NMT | Inconsistent | Moderate | Requires significant added controls |
Specialized LLM (domain-adapted) | Enforced via Term Bases | Document-level | Designed for regulated workflows |
What governance and traceability frameworks does LLM-based compliance translation require?
Translation governance is a proactive lifecycle process that embeds auditability and human checks rather than functioning as a reactive checklist. Compliance professionals deploying LLMs in regulatory translation need to build governance into the workflow architecture, not bolt it on afterward.
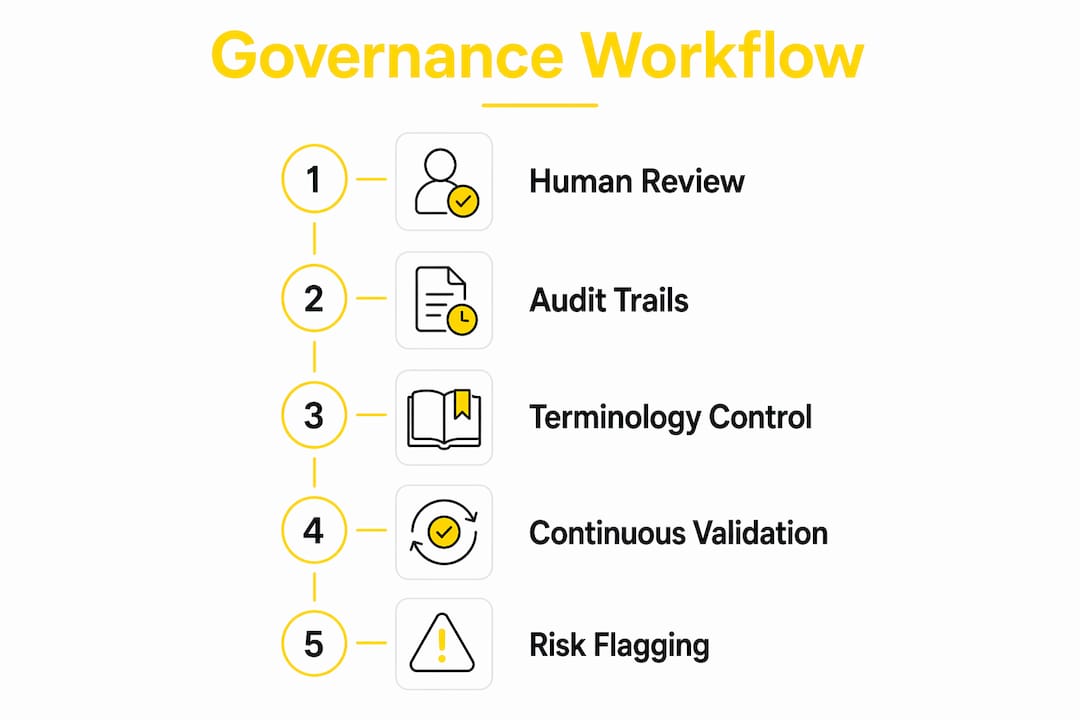
The EU AI Act classifies AI systems used in legal and regulatory document generation as high-risk. Regulatory requirements like the EU AI Act mandate human oversight and labeling of AI-generated content in high-risk legal and regulatory documents. Non-compliance risks include penalties and submission delays. By 2026, these requirements are accelerating formal adoption of human oversight and traceability in AI-assisted compliance translation workflows.
The core governance controls for LLM-based compliance translation are:
Human-in-the-loop checkpoints. Certified subject-matter experts review every AI-generated draft before it enters a regulatory submission.
Terminology governance. AI output is constrained by client-approved Term Bases (TB) and Translation Memories ™ to prevent unauthorized term substitution.
Data processing agreements. Contractual safeguards must explicitly prevent use of client submission content for model training to protect sensitive regulatory data.
Audit trails. Traceability in AI translation involves recording model versions, edits, and human review history to ensure full auditability for regulators.
ISO 18587 alignment. This standard addresses machine translation post-edit quality and governance, setting the baseline for acceptable human review processes.
Pro Tip: Anticipate hallucination risks before they reach a reviewer. Configure your LLM system to flag low-confidence outputs and route them to a senior terminologist rather than a standard linguist. This single control prevents the most costly class of compliance errors.
How to implement an AI+HUMAN hybrid translation workflow for regulatory documents
The AI+HUMAN hybrid translation model assigns AI the initial draft generation and human experts the roles of linguistic review, regulatory verification, and final audit. Human roles shift from translating to quality gatekeeping. That shift is what makes the speed gains possible without sacrificing compliance.
A well-structured workflow for regulated document translation follows this sequence:
Asset integration. Ingest client Translation Memories ™ and Term Bases (TB) before any AI generation begins. This step constrains the model to approved terminology from the first token.
LLM generation. The proprietary LLM-based system produces target language output constrained by client terminology and style guidance. No general-purpose public model processes the content.
Subject-matter expert review. A certified expert reviews the draft for technical accuracy, regulatory compliance, and contextual nuance. In life sciences, this reviewer holds domain credentials, not just linguistic ones.
Quality assurance. QA is aligned to ISO 17100 and ISO 18587 and, where relevant, sector requirements such as MDR. This step produces the audit documentation regulators expect.
Final delivery and audit log. The completed translation is delivered alongside a full record of model version, human edits, and QA sign-off.
AD VERBUM’s LangOps System follows this exact sequence across 150+ languages, with all processing on private EU-hosted infrastructure. The result, per AD VERBUM’s stated figures, is a turnaround 3x to 5x faster than traditional workflows with compliance controls intact.
Pro Tip: Update your Term Base after every major regulatory guidance revision. Agencies like the FDA and EMA update preferred terminology in guidance documents regularly. A glossary that is six months out of date is a terminology drift risk waiting to surface in a submission.
Terminologists, linguists, and regulatory specialists each play distinct roles in this process. Terminologists own the TB and flag new terms. Linguists execute the post-edit review. Regulatory specialists verify that translated content aligns with the target market’s current regulatory expectations. Collapsing these roles into one reviewer is the most common workflow failure in compliance translation programs.
What are the most common failure modes in LLM-based compliance translation?
Typical failure modes include terminology drift, AI hallucinations, and ungoverned AI use, all of which can lead to regulatory delays or penalties. Failures in this category can necessitate costly resubmissions. A resubmission to the EMA or FDA is not just a cost event. It is a timeline event that can delay market entry by quarters.
The failure patterns break down as follows:
Terminology drift. A general LLM substitutes a near-synonym for a controlled term. The substitution passes linguistic review but fails regulatory review because the target agency uses the original term as a defined concept.
AI hallucinations. The model generates plausible-sounding but factually incorrect content, particularly in dosage instructions, contraindication lists, or financial risk disclosures.
Ungoverned AI use. A team uses a public NMT or general LLM tool without data processing agreements, exposing submission content to potential model training ingestion.
Insufficient human oversight. Reviewers are given too many documents per session, reducing the quality of post-edit review to a surface-level check rather than a regulatory verification.
Stale glossaries. Term Bases are not updated after regulatory guidance changes, causing the model to generate output that was compliant six months ago but is not compliant today.
Mitigation relies on domain-specific AI, human oversight, terminology enforcement, and continuous validation. Proactive glossary management is the single most effective control for reducing terminology drift risk. The importance of terminology enforcement in regulated translation cannot be separated from the AI governance question. They are the same problem.
Key Takeaways
LLMs improve compliance translation speed and accuracy only when embedded in governed, domain-specific AI+HUMAN hybrid workflows with enforced terminology controls and full audit traceability.
Point | Details |
Domain specialization is non-negotiable | General-purpose LLMs produce terminology drift; only domain-adapted models with enforced Term Bases are suitable for regulated content. |
Governance must be built in, not added on | Audit trails, data processing agreements, and ISO 18587-aligned QA must be part of the workflow architecture from the start. |
Human oversight is a regulatory requirement | The EU AI Act classifies regulatory document AI as high-risk, mandating human review and labeling of AI-generated content. |
Speed gains require structured workflows | The 3x to 5x turnaround improvement depends on a defined sequence: asset integration, LLM generation, SME review, and QA. |
Stale glossaries are a compliance risk | Term Bases must be updated after every regulatory guidance revision to prevent outdated terminology from entering submissions. |
Where AI translation is heading in regulated industries
The compliance translation field is at an inflection point, and I say that based on watching the same pattern repeat across pharmaceutical and financial clients for years. Teams adopt AI tools for the speed. They encounter their first regulatory challenge when a submission is queried over a terminology inconsistency. Then they rebuild the workflow with proper governance. The sequence is predictable and avoidable.
The teams that get this right early share one characteristic: they treat terminology governance as infrastructure, not as a project. They invest in Term Bases the way they invest in document management systems. They assign ownership, set update schedules, and audit the glossary the same way they audit the translation itself. That discipline is what separates a compliant AI translation program from a fast one that eventually fails a regulatory review.
The EU AI Act will force the rest of the market to catch up. By 2026, formal human oversight requirements for high-risk AI systems are no longer optional guidance. They are enforceable obligations. Compliance professionals who have already built human-in-the-loop controls into their translation workflows will find the transition straightforward. Those who have not will face both a compliance gap and a competitive one.
My practical recommendation: evaluate your current translation vendor on three criteria before anything else. Does their AI system process your data on private infrastructure with explicit contractual protections against model training? Do they maintain a certified subject-matter expert review at every stage? And can they produce a full audit trail that a regulator can follow from source document to final translation? If the answer to any of those is no, the speed advantage they offer is not worth the risk.
— Eric Brown
How AD VERBUM handles compliance translation for regulated industries
AD VERBUM’s compliance-focused localization services are built on a proprietary LangOps System hosted on private EU servers, with ISO 27001 certification and no reliance on outsourced public cloud tooling for core processing. Every translation follows the AI+HUMAN hybrid translation workflow: asset integration, LLM generation constrained by client Term Bases, certified subject-matter expert review, and QA aligned to ISO 17100, ISO 18587, and MDR where applicable.
AD VERBUM serves life sciences, finance, legal, defense, and manufacturing clients across 150+ languages. The network includes 3,500+ subject-matter expert linguists, including medical professionals, engineers, and legal scholars. For compliance professionals who need turnaround speed without sacrificing audit readiness, AD VERBUM’s AI+HUMAN translation process delivers both within a fully governed, GDPR and HIPAA-aligned framework.
FAQ
What is the role of LLMs in compliance translation?
LLMs generate accurate regulatory document drafts faster than traditional methods by following explicit terminology and style instructions. Their role is to accelerate the drafting stage while human experts handle regulatory verification and QA.
How do specialized LLMs differ from general-purpose models in regulatory translation?
Specialized LLMs are fine-tuned on domain-specific regulatory corpora and constrained by client-approved Term Bases, which eliminates the terminology drift that general-purpose models produce in compliance contexts.
What governance controls are required for LLM-based compliance translation?
Required controls include human-in-the-loop review, audit trails recording model versions and edits, data processing agreements preventing model training on client content, and QA aligned to ISO 18587.
Does the EU AI Act apply to AI-assisted regulatory translation?
Yes. The EU AI Act classifies AI systems used in high-risk legal and regulatory document generation as high-risk, mandating human oversight, content labeling, and full traceability of AI-generated outputs.
What causes terminology drift in AI compliance translation?
Terminology drift occurs when a general-purpose LLM substitutes a near-synonym for a controlled regulatory term. It is prevented by enforcing client-approved Term Bases at the model input stage and updating glossaries after every regulatory guidance revision.
Recommended