
Machine Translation Risks 2025: Security and Compliance Impact
- Dec 17, 2025
- 7 min read

Most American businesses now rely on machine translation to break language barriers, yet nearly 60 percent underestimate its risks and limitations. Rapid advancements in translation technology promise unprecedented access, but confusion and false confidence persist. This guide uncovers what sets each machine translation approach apart, tackles the most common myths, and highlights why precision, security, and human oversight matter more than ever for American companies.
Table of Contents
Key Takeaways
Point | Details |
Understanding Machine Translation Models | Machine translation encompasses various models, including Legacy MT, NMT, and LLM-Based AI, each with differing strengths and limitations. Evaluate these based on specific domain needs. |
Verification Importance | Always have human experts review machine-generated translations, especially in high-stakes industries like legal and medical, to prevent misunderstandings. |
Data Security Risks | Be aware of data vulnerabilities in translation technologies, including unauthorized content exposure and linguistic hallucinations, particularly in regulated sectors. |
Terminology Management | Develop a robust terminology database to ensure consistency and accuracy in specialized translations, addressing compliance gaps effectively. |
Defining Machine Translation and Common Misconceptions
Machine translation represents a complex technological landscape where linguistic processing meets computational power. Unlike traditional human translation, machine translation attempts to automatically convert text from one language to another using sophisticated algorithms and computational models.
Modern machine translation technologies can be broadly categorized into three primary models, as revealed by recent scoping review research: linguistic processor, mediational artifact, and translanguaging process. Each model approaches language conversion differently, presenting unique strengths and inherent limitations. The linguistic processor model focuses on direct word-for-word translation, while the mediational artifact approach considers broader contextual nuances, and the translanguaging process explores dynamic language interaction.
Common misconceptions about machine translation often stem from overestimating its capabilities. Many professionals mistakenly believe machine translation can perfectly replicate human linguistic understanding. In reality, machine translation struggles with complex linguistic elements like:
Contextual nuances
Idiomatic expressions
Cultural references
Technical terminology
Grammatical subtleties
These limitations become particularly critical in high-stakes industries like legal, medical, and technical documentation, where precision is paramount. Automated translations can introduce significant risks if not carefully vetted by subject matter experts.
Pro Tip - Translation Verification: Always have a human expert review machine-generated translations, especially for documents involving technical, legal, or sensitive content to minimize potential misunderstandings or critical errors.
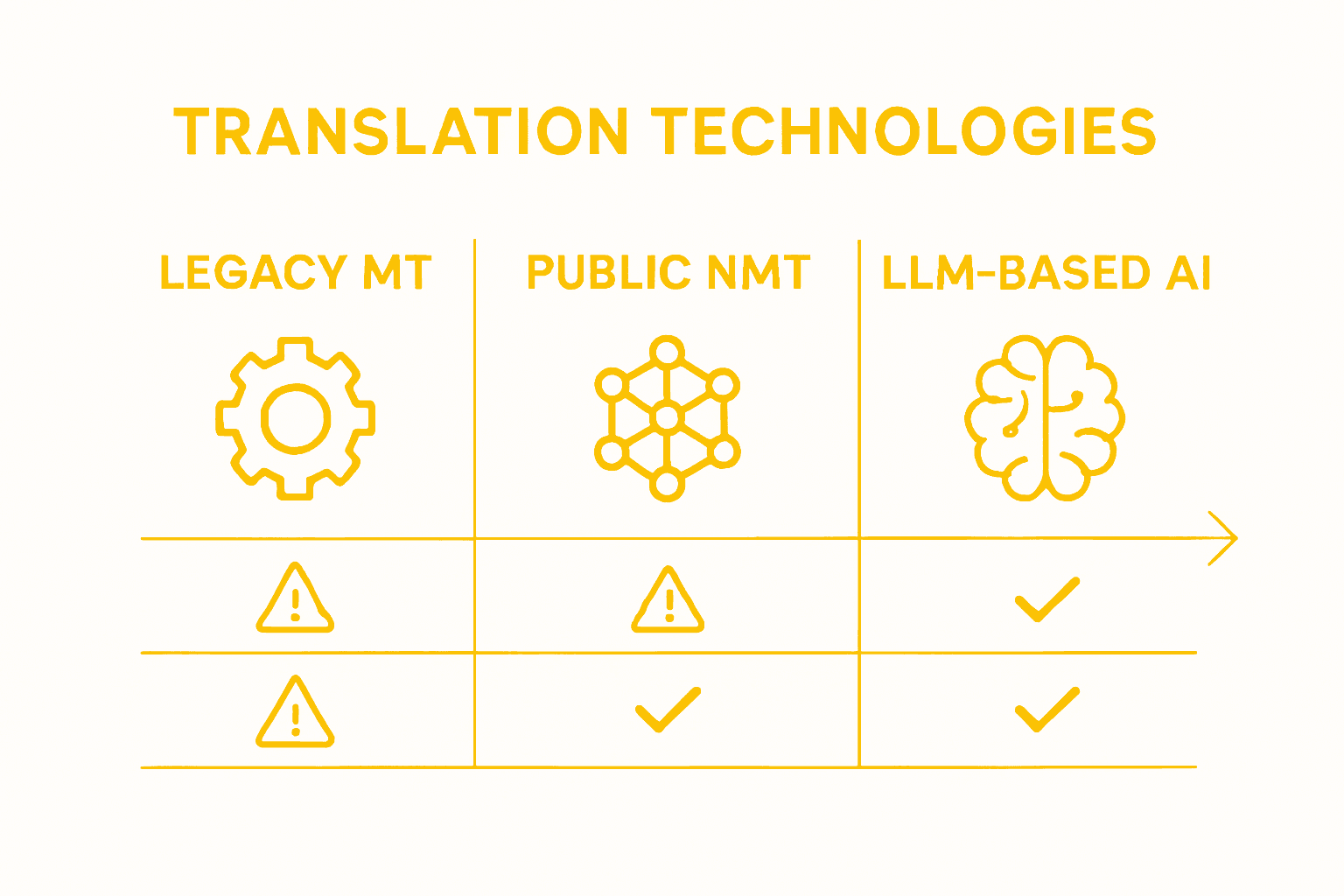
Legacy MT, NMT, and LLM-Based AI Compared
The evolution of translation technologies reveals a fascinating progression from basic mechanical approaches to sophisticated artificial intelligence systems. Comprehensive technological surveys demonstrate significant transformations in machine translation methodologies, each representing a distinct approach to linguistic conversion.
Legacy Machine Translation (MT) represents the earliest computational approach to translation. These systems relied on rigid rule-based algorithms and direct word-for-word substitution, often producing grammatically incorrect and contextually nonsensical translations. Key characteristics of legacy MT include:
Strict grammatical rule implementation
Limited vocabulary databases
Minimal contextual understanding
High error rates in complex linguistic structures
Inability to handle idiomatic expressions
Neural Machine Translation (NMT), the next evolutionary step, introduced statistical learning models that could analyze broader linguistic patterns. These systems, like Google Translate, utilize neural networks to generate more contextually aware translations. However, they still suffer from significant limitations, particularly in specialized or technical domains.
Large Language Model (LLM)-Based AI Translation represents the cutting-edge frontier of linguistic conversion technologies. Unlike previous methods, advanced deep learning approaches enable these systems to understand nuanced context, cultural implications, and complex grammatical structures with unprecedented accuracy. LLM-based systems can dynamically interpret linguistic subtleties that earlier translation technologies completely missed.

Pro Tip - Translation Technology Selection: Always evaluate translation technologies based on your specific domain requirements, understanding that no single solution fits all linguistic conversion needs.
Here is a comparison of the main machine translation technologies and their suitability for specialized business contexts:
Translation Technology | Context Understanding | Customization Potential | Suitable Use Cases |
Legacy MT | Very limited | Minimal | Simple documents, bulk text |
Neural MT | Moderate, general domains | Moderate via glossaries | Routine communications |
LLM-Based AI Translation | Advanced, nuanced, adaptable | High with training | Legal, medical, technical |
Proprietary AI+HUMAN Mix | Superior, domain-specific | Maximum with oversight | Highly regulated industries |
Data Security and Privacy Risks in 2025
The landscape of machine translation is increasingly fraught with complex data security and privacy challenges that demand unprecedented scrutiny. Comprehensive research investigations reveal multiple critical vulnerabilities inherent in current translation technologies, highlighting the potential for sensitive information exposure.
Data Vulnerability Vectors in machine translation systems emerge through several sophisticated mechanisms:
Uncontrolled data transmission across public cloud platforms
Potential unauthorized storage of translated content
Risk of linguistic model training using proprietary information
Lack of robust encryption in translation pipelines
Potential cross-contamination between translation requests
One of the most alarming risks involves linguistic hallucinations, where translation systems inadvertently generate or modify content without user awareness. Recent studies on multilingual translation models demonstrate that these hallucinations can introduce significant security risks, potentially revealing or distorting sensitive information during the translation process.
For organizations operating in regulated industries like healthcare, legal, and finance, these risks are particularly acute. Public machine translation platforms often lack the robust security protocols necessary to protect confidential information, creating potential compliance violations and exposing organizations to substantial legal and reputational damage.
Pro Tip - Translation Security Audit: Conduct quarterly comprehensive security assessments of your translation technologies, focusing on data transmission protocols, storage mechanisms, and potential information leakage points.
Below is a quick reference for data security priorities when selecting machine translation platforms:
Risk Factor | Why It Matters | Mitigation Priority |
Data Leakage | Protects confidential information | Highest |
Model Training on Your Data | Prevents IP exposure | High |
Lack of Encryption | Shields content in transit/storage | High |
Linguistic Hallucinations | Prevents misinformation risks | Critical in sensitive fields |
Cross-Request Contamination | Avoids mixing of client data | Vital for compliance |
Terminology Enforcement: Critical Compliance Gaps
Terminology enforcement represents a critical battleground in machine translation, where precision can mean the difference between accurate communication and catastrophic misunderstandings. Innovative research exploring gender-neutral translation approaches highlights the complex challenges of maintaining consistent linguistic standards across diverse translation platforms.
Compliance Gaps in terminology management emerge through multiple critical vectors:
Inconsistent terminology databases
Lack of centralized linguistic governance
Insufficient domain-specific vocabulary control
Absence of real-time terminology validation mechanisms
Limited contextual understanding in translation models
The translation industry faces significant challenges in maintaining terminology consistency, particularly in highly regulated sectors. Comprehensive studies examining translator training programs reveal substantial misalignments between academic preparation and industry-specific terminology requirements. These gaps can create substantial risks, especially in fields like medical, legal, and technical documentation where a single mistranslated term can have profound consequences.
Most public machine translation platforms lack sophisticated terminology enforcement mechanisms. They rely on generic translation models that cannot guarantee precise, context-specific terminology usage. This limitation becomes particularly critical in industries where technical precision is paramount, such as pharmaceutical research, aerospace engineering, and international legal documentation.
Pro Tip - Terminology Management: Develop a comprehensive, regularly updated terminology database that incorporates domain-specific vocabulary and enforces strict linguistic consistency across all translation workflows.
Mitigating Risks with Proprietary AI+HUMAN Workflows
The AI+HUMAN workflow represents a sophisticated approach to translation that directly addresses the critical vulnerabilities inherent in traditional machine translation systems. Research examining self-regulated AI tool integration underscores the paramount importance of human oversight in maintaining translation accuracy and reliability.
Key components of an effective AI+HUMAN risk mitigation strategy include:
Strict human validation of AI-generated translations
Continuous refinement of proprietary linguistic models
Domain-specific expert review processes
Real-time error detection and correction mechanisms
Comprehensive contextual understanding protocols
The complexity of modern translation requires more than simple algorithmic conversion. Specialized studies in audiovisual translation environments reveal that collaborative approaches between AI systems and human experts can dramatically reduce translation risks. This synergy allows for nuanced understanding that pure machine translation systems fundamentally lack, particularly in specialized or regulated industries where precision is absolutely critical.
Proprietary AI+HUMAN workflows distinguish themselves by implementing multiple layers of linguistic and contextual verification. Unlike public translation platforms, these advanced systems integrate subject matter experts directly into the translation pipeline, ensuring that each translation undergoes rigorous human validation. This approach transforms translation from a mechanical process to an intelligent, adaptive workflow that can navigate complex linguistic and cultural landscapes with unprecedented accuracy.
Pro Tip - Workflow Integration: Develop a multi-stage review process that leverages both AI capabilities and human expertise, creating a dynamic translation ecosystem that continuously learns and improves.
Secure Your Translations with Proven AI+HUMAN Precision
The article underscores critical machine translation risks in 2025 including data leakage, terminology enforcement gaps, and compliance failures that threaten sensitive industries. If you handle confidential medical, legal, or technical content, relying on public Neural Machine Translation or legacy MT exposes your organization to serious security breaches and costly errors.
AD VERBUM offers a superior solution built exactly to meet these risks head-on. Our proprietary LLM-based AI ecosystem runs within secure ISO 27001 certified EU infrastructure assuring zero data leakage and full compliance with GDPR and HIPAA. Combined with our stringent AI+HUMAN workflow, where 3,500+ subject matter experts validate every project, we guarantee accurate terminology enforcement and contextual precision unmatched by public platforms.
Choose a translation partner designed for regulated industries that cannot afford mistranslations or security vulnerabilities. Learn more about our Specialized AI Translation services and why AD VERBUM’s proprietary technology defines the future of safe, compliant machine translation. Act now to protect your sensitive information and ensure flawless regulatory adherence.
Frequently Asked Questions
What are the main risks associated with machine translation in 2025?
The primary risks include data leakage, unauthorized storage of translated content, lack of robust encryption, linguistic hallucinations leading to misinformation, and cross-request contamination of data.
How can organizations mitigate data security risks in machine translation?
Organizations can mitigate risks by conducting comprehensive security audits, utilizing platforms with robust encryption protocols, and ensuring that sensitive data is not used in model training without proper safeguards.
Why is terminology enforcement important in machine translation?
Terminology enforcement is critical to maintain consistency and precision in translations, particularly in regulated industries like healthcare and law, where a single mistranslated term can have serious consequences.
What is the advantage of an AI+HUMAN translation workflow?
The AI+HUMAN workflow combines the efficiency of AI with the accuracy of human oversight, allowing for nuanced understanding and verification of translations, significantly reducing risks in specialized fields.
Recommended