
Kontextbasierte maschinelle Übersetzung für Fachkräfte
- 18. Mai
- 7 Min. Lesezeit

Viele Fachkräfte in Pharma, Recht und Finanzdienstleistungen begegnen KI-gestützten Übersetzungen mit berechtigter Skepsis: zu ungenau, zu riskant, nicht DSGVO-konform. Doch diese Einschätzung trifft nur auf ältere Systeme zu. Wie funktioniert kontextbasierte maschinelle Übersetzung tatsächlich, und warum ist sie für regulierte Branchen relevant? Moderne kontextbasierte Übersetzung nutzt nicht einzelne Wörter isoliert, sondern verarbeitet den gesamten sprachlichen Umfeld eines Satzes. Das Ergebnis ist eine semantisch präzise Übersetzung, die auch komplexe Fachbegriffe korrekt wiedergibt. Dieser Artikel erklärt die Technologie, den Workflow und den Datenschutz verständlich und konkret.
Inhaltsverzeichnis
Kontextbasierte maschinelle Übersetzung in regulierten Branchen: Workflow und Compliance
Retrieval-Augmented Generation (RAG) und Datenschutz in kontextbasierter maschineller Übersetzung
Die Rolle von Kontextmanagement für präzise und sichere Fachübersetzungen
Professionelle Übersetzung mit AD VERBUM: KI-gestützt und sicher für regulierte Branchen
Häufig gestellte Fragen zur kontextbasierten maschinellen Übersetzung
Grundlagen der kontextbasierten maschinellen Übersetzung
Kontextbasierte maschinelle Übersetzung beginnt dort, wo klassische regelbasierte Systeme versagen: bei Mehrdeutigkeit. Das Wort “Bank” bedeutet auf Deutsch sowohl Geldinstitut als auch Sitzgelegenheit. Ein regelbasiertes System übersetzt mechanisch. Ein neuronales System liest den Satz als Ganzes und trifft die richtige Wahl.
Kontextbasierte maschinelle Übersetzung nutzt moderne neuronale MT so, dass die Bedeutung anhand des gesamten Satzes und Umfelds vorhergesagt wird, statt isolierte Wörter oder Phrasen wortwörtlich zu ersetzen. Das ist der Kern des Unterschieds zu älteren Maschinelle Übersetzung Methoden.
Wie neuronale maschinelle Übersetzung (NMT) technisch funktioniert
Neuronale maschinelle Übersetzung arbeitet end-to-end mit Deep Learning. Das bedeutet: Das Modell nimmt einen vollständigen Quellsatz auf, analysiert jedes Token in Relation zu allen anderen Tokens und erzeugt dann die Zielsprache. Kein manuell definiertes Wörterbuch, keine starren Grammatikregeln.
Die algorithmischen Übersetzungstechniken dahinter basieren auf sogenannten Transformer-Architekturen. Diese Modelle nutzen Aufmerksamkeitsmechanismen (englisch: Attention Mechanisms), die bestimmen, welche Teile des Satzes für die Übersetzung eines bestimmten Wortes besonders relevant sind. Bei der Übersetzung von “Die Klage wurde abgewiesen” erkennt das Modell, dass “Klage” hier juridisch gemeint ist, nicht im Sinne von Beschwerde.
Die kontextuelle Sprachverarbeitung umfasst dabei:
Satzstruktur: Satzbau und Satzlänge beeinflussen die Wahl von Zielkonstruktionen.
Semantischer Umfeld: Welche Wörter stehen in der Nähe des zu übersetzenden Begriffs?
Domänenkontext: In einem medizinischen Dokument bedeutet “Suspension” etwas anderes als in einem juristischen.
Dokumentenweiter Kontext: Moderne LLM-basierte Systeme berücksichtigen sogar mehrere Absätze gleichzeitig.
Terminologische Konsistenz: Verwendete Fachbegriffe müssen über das gesamte Dokument hinweg einheitlich bleiben.
Ein konkretes maschinelle Übersetzung Beispiel: In einem klinischen Studienbericht erscheint der Begriff “adverse event” durchgehend. Ohne Kontextsteuerung könnte ein System das einmal als “unerwünschtes Ereignis” und einmal als “Nebenwirkung” übersetzen. Beide Übersetzungen sind im Prinzip möglich, aber regulatorisch ist nur eine davon für das jeweilige Dokument zulässig.

Kontextbasierte maschinelle Übersetzung in regulierten Branchen: Workflow und Compliance
Nachdem die technischen Grundlagen klar sind, stellt sich die entscheidende Frage für Fachkräfte: Wie sieht ein Workflow aus, der kontextbasierte Übersetzung mit Compliance-Anforderungen verbindet? Die Antwort liegt nicht in der Technologie allein, sondern in der strukturierten Abfolge von Schritten.
Für regulierte Inhalte setzen viele Organisationen kontextbasierte MT im Workflow als “Humans-on-the-loop” ein: Zuerst werden Terminologie und Formatierung vorbereitet, danach generiert die NMT-Engine die syntaktische Satzstruktur, und anschließend erfolgt Qualitätskontrolle mit klaren Eskalationswegen für Compliance-Risiken.
Der typische Workflow in fünf Schritten
Terminologie- und Formatvorbereitung: Bevor die KI auch nur einen Satz sieht, werden Terminologiedatenbanken (TB) und Styleguides eingespielt. Was als “Wirkstoff” gilt, was als “aktiver Bestandteil”, ist vorab definiert. Das verhindert kontextuelle Fehlentscheidungen des Modells von Anfang an.
NMT-Generierung auf Basis des Kontexts: Die Engine übersetzt nicht Satz für Satz unabhängig, sondern bezieht den gesamten verfügbaren Dokumentkontext ein. Das Ergebnis ist grammatisch und semantisch kohärent über Absätze hinweg.
Automatische Qualitätsprüfung: Terminologiefehler, fehlende Übersetzungssegmente und Formatbrüche werden algorithmisch erkannt. Das ist kein menschlicher Schritt, aber ein wichtiges Sicherheitsnetz vor der Humanprüfung.
Menschliche Prüfung durch Fachexperten: Ein zertifizierter Linguist mit Fachkenntnissen im jeweiligen Bereich prüft die Ausgabe. Bei einer Zulassungsdokumentation für Medizinprodukte ist das jemand, der die MDR-Anforderungen kennt und nicht nur Sprache beherrscht. Dieser Schritt ist für regulierte Qualitätsprüfung Compliance nicht optional.
Eskalation und Freigabe: Inhalte mit erhöhtem Compliance-Risiko, zum Beispiel Warnhinweise auf Medizinprodukten oder Haftungsausschlüsse in Verträgen, durchlaufen einen gesonderten Freigabeprozess. Klare Eskalationswege garantieren, dass kritische Fehler nicht unbemerkt bleiben. Mehr dazu, wie dieser Prozess sicher und konform umgesetzt wird, zeigt der verlinkte Leitfaden.
Profi-Tipp: Terminologiemanagement sollte nicht am Ende des Projekts starten. Wer Glossare und Terminologiedatenbanken vor Projektbeginn befüllt, spart durchschnittlich 20 bis 30 Prozent an Nacharbeit und erhöht die Konsistenz über alle Sprachversionen hinweg.
Retrieval-Augmented Generation (RAG) und Datenschutz in kontextbasierter maschineller Übersetzung
RAG ist eine der wichtigsten Entwicklungen im Bereich der kontextbasierten Übersetzung, und gleichzeitig eine der am meisten missverstandenen. Das Prinzip ist folgendes: Statt das Sprachmodell mit einem statischen Trainings-Wissen arbeiten zu lassen, wird es vor der Generierung mit relevantem Referenzmaterial angereichert.
In RAG-ähnlichen Ansätzen wird der Kontext vor der Generierung gezielt über Such- und Retrieval-Schritte aus Referenzdokumenten ergänzt. Für die Übersetzung bedeutet das: Das Modell kann auf firmenspezifische Handbücher, frühere Übersetzungen oder regulatorische Leitfäden zugreifen, bevor es das Zielsegment erzeugt. Das reduziert Halluzinationen erheblich.
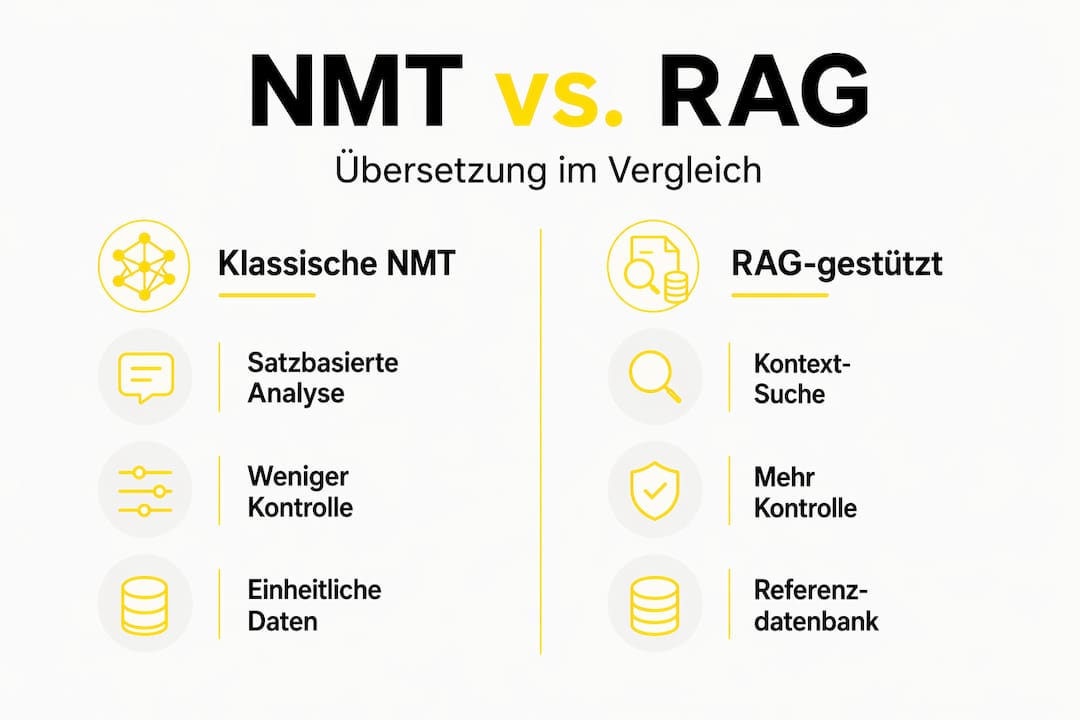
Klassische NMT vs. RAG-gestützte Übersetzung im Vergleich
Merkmal | Klassische NMT | RAG-gestützte Übersetzung |
Wissensquelle | Statisches Trainingsmodell | Dynamisch abgerufene Referenzdokumente |
Terminologietreue | Gering, abhängig von Trainingsdaten | Hoch, da firmeneigene Glossare genutzt werden |
Halluzinationsrisiko | Erhöht | Deutlich reduziert |
Datenkontrolle | Keine (öffentliche Modelle) | Vollständig (eigene Vektordatenbank) |
Compliance-Tauglichkeit | Nicht empfohlen für regulierte Branchen | Geeignet bei korrekter Governance |
Auditierbarkeit | Nicht gewährleistet | Nachvollziehbar über Referenzpfade |
“Datenschutzrechtlich ist RAG keine Wunderlösung, aber kann zentrale Datenschutzgrundsätze unterstützen, unter anderem weil Referenzdokumente und die Vektordatenbank kontrolliert werden können.”
Das ist ein entscheidender Punkt für Fachkräfte in regulierten Branchen. RAG verschafft Kontrolle über das Quellmaterial des Modells. Wer die Vektordatenbank selbst hostet und befüllt, kann sicherstellen, dass keine vertraulichen Patientendaten oder unveröffentlichte Patentdokumente unkontrolliert in öffentliche Systeme fließen.
Gleichzeitig gilt: Gutes Dokumentenmanagement ist Pflicht. Welche Referenzdokumente dürfen in die Datenbank? Wer hat Zugriffsrechte? Wie werden Dokumente aus dem System entfernt, wenn Betroffene ihre Rechte geltend machen? Diese Governance-Fragen sind nicht technischer, sondern organisatorischer Natur und müssen vor dem Einsatz von RAG geklärt sein.
Eine umfassende Analyse der Qualitätssicherung für regulierte Branchen zeigt, wie diese Governance-Strukturen in der Praxis aussehen.
Die Rolle von Kontextmanagement für präzise und sichere Fachübersetzungen
Technologie kann nur so gut sein wie die Daten und Strukturen, die ihr zugrunde liegen. Das gilt nirgendwo so klar wie in der Fachübersetzung für regulierte Branchen. Selbst das präziseste LLM erzeugt inkonsistente Ergebnisse, wenn das Kontextmanagement fehlt.
In professionellen MT-Workflows wird Kontext oft operationalisiert: Statt nur den Satz einzeln zu übersetzen, wird über Translation Memory ™ und Terminologiemanagement eine projektweite Konsistenz geschaffen. Das reduziert kosmetische Änderungen, die in regulierten Dokumenten über mehrere Abschnitte und Versionen hinweg auditfähig bleiben müssen.
Was gutes Kontextmanagement in der Praxis bedeutet
Translation Memory ™ als kollektives Gedächtnis: Jede freigegebene Übersetzung wird gespeichert und steht künftigen Projekten zur Verfügung. Wenn “Gebrauchsanweisung für Medizinprodukt Typ A” schon zweimal mit denselben Formulierungen übersetzt wurde, muss das Modell das Rad nicht neu erfinden.
Terminologiedatenbanken als Regelwerk: Freigegebene Begriffe, verbotene Terme und bevorzugte Formulierungen sind explizit hinterlegt. Das Modell folgt diesen Vorgaben, nicht seinem statistischen Instinkt.
Projektkontext vs. Arbeitskontext: Der Projektkontext enthält Metadaten wie Zielmarkt, Dokumenttyp und regulatorischen Rahmen. Der Arbeitskontext enthält die bisherigen Segmente des aktuellen Dokuments. Beide müssen klar getrennt und aktiv verwaltet werden.
Versionierung für Auditfähigkeit: Regulierte Dokumente wie EU-MDR-Zulassungsunterlagen oder Kreditverträge durchlaufen mehrere Versionen. Jede Übersetzungsentscheidung muss nachvollziehbar bleiben. Ein gutes TM-System protokolliert, welche Segmentversion wann von wem freigegeben wurde.
Konsistenz über Sprachversionen hinweg: Ein klinisches Studiendokument erscheint in fünf Sprachen. Eine Inkonsistenz in einer Version kann bei einer regulatorischen Prüfung als Widerspruch gewertet werden. Translation Memory verhindert das systematisch.
Profi-Tipp: Bei langen Projekten empfiehlt sich eine regelmäßige “Context-Hygiene”: Überprüfen Sie alle sechs Monate, ob Terminologieeinträge noch aktuell sind, veraltete TM-Segmente deaktiviert wurden und der Projektkontext noch dem regulatorischen Stand entspricht. Das ist keine administrative Pflicht, sondern ein aktives Qualitätsinstrument.
Wie ein strukturierter Übersetzungsworkflow für regulatorische Dokumente konkret aufgebaut sein sollte, zeigt der verlinkte Leitfaden mit Schritt-für-Schritt-Erklärungen.
Warum Workflow und Governance wichtiger sind als reine Technologie bei kontextbasierter maschineller Übersetzung
Nach der technischen und prozessualen Analyse folgt eine Einschätzung, die unbequem ist, aber notwendig: Die meisten Fehler in regulierten Übersetzungsprojekten entstehen nicht, weil das KI-Modell zu schwach war. Sie entstehen, weil der Workflow dahinter nicht funktioniert.
Der entscheidende Unterschied in regulierten Branchen liegt meist nicht beim Modell allein, sondern beim Workflow: Terminologie- und TM-Steuerung, Qualitätsprüfung und Eskalationswege entscheiden darüber, ob kontextbasierte MT wirklich vertrauenswürdig in Compliance-Umgebungen eingesetzt werden kann.
Wir beobachten in der Praxis immer wieder dasselbe Muster: Unternehmen investieren in leistungsstarke KI-Systeme und vernachlässigen gleichzeitig die Terminologiepflege. Das Ergebnis ist ein System, das sprachlich brillant klingt, aber falsche Fachbegriffe verwendet. Ein pharmakologisches Dokument, das “Wirkstoffkonzentration” und “Dosierung” synonym behandelt, ist nicht nur inkonsistent. Es ist ein Zulassungsrisiko.
Die Überbewertung des Algorithmus ist verständlich. Modelle wie moderne LLMs sind beeindruckend. Aber ein LLM, das auf eine schlecht gepflegte Terminologiedatenbank trifft, arbeitet mit veralteten oder widersprüchlichen Anweisungen. Das ist wie ein hochqualifizierter Übersetzer, dem man ein unlesbares Briefing gibt.
Der zweite Punkt ist Governance. In der Qualitätssicherung für regulierte Branchen bedeutet das: Wer hat die Autorität, Terminologie freizugeben? Welche Dokumente dürfen in das RAG-System? Wer prüft die finale Übersetzung gegen den regulatorischen Standard? Diese Fragen müssen vor dem ersten Übersetzungsauftrag beantwortet sein.
Technologie ist ein Werkzeug. Ein sehr gutes, aber immer noch ein Werkzeug. Die Fachkräfte, die es einsetzen, und die Prozesse, die es umgeben, entscheiden über Erfolg oder Haftung.
Professionelle Übersetzung mit AD VERBUM: KI-gestützt und sicher für regulierte Branchen
Nach allem, was Sie über Kontextsteuerung, RAG-Technologie und Workflow-Compliance gelesen haben, stellt sich die praktische Frage: Welcher Anbieter setzt das alles tatsächlich um?

AD VERBUM verbindet über 25 Jahre Branchenerfahrung mit einem proprietären LLM-basierten KI-System, das ausschließlich auf EU-Servern betrieben wird. Der AI+HUMAN Workflow stellt sicher, dass jede Übersetzung sowohl algorithmisch optimiert als auch von einem zertifizierten Fachexperten geprüft wird. Für Pharma-Unternehmen bedeutet das MDR-konforme Dokumentation. Für Kanzleien bedeutet es juristische Präzision ohne DSGVO-Risiko. Das professionelle Übersetzungsangebot von AD VERBUM deckt über 150 Sprachen ab, inklusive Dialektvarianten, mit nachvollziehbarer Audit-Trail-Dokumentation. Entdecken Sie alle AD VERBUM Services oder erfahren Sie direkt, wie der Übersetzungs-Workflow im Detail aufgebaut ist. Weil in regulierten Branchen jede Fehlentscheidung Konsequenzen hat.
Häufig gestellte Fragen zur kontextbasierten maschinellen Übersetzung
Was unterscheidet kontextbasierte maschinelle Übersetzung von herkömmlicher maschineller Übersetzung?
Kontextbasierte MT nutzt den gesamten Satz- und Dokumentumfeld, um Bedeutungen präzise vorherzusagen, während herkömmliche Methoden Wörter oder Phrasen oft isoliert und damit mehrdeutig behandeln.
Wie sorgt AD VERBUM für Compliance bei maschinellen Übersetzungen in regulierten Branchen?
AD VERBUM setzt auf den AI+HUMAN Workflow mit integriertem Terminologiemanagement, Translation Memory und menschlicher Fachprüfung. Für regulierte Inhalte sind klare Eskalationswege für Compliance-kritische Segmente fest im Prozess verankert.
Was sind die datenschutzrechtlichen Vorteile des Einsatzes von RAG in Übersetzungs-Workflows?
RAG ermöglicht vollständige Kontrolle über Referenzdokumente und Vektordatenbanken. Datenschutzrechtlich ist es keine Universallösung, unterstützt aber zentrale DSGVO-Grundsätze, sofern eine sorgfältige Governance und eine Einzelfallprüfung sichergestellt sind.
Warum ist Kontextmanagement für Fachübersetzungen so wichtig?
Projektweites Kontextmanagement über Translation Memory und Terminologie verhindert inkonsistente Übersetzungen, unterstützt die Auditierbarkeit regulatorischer Dokumente und senkt das Risiko von Compliance-Verstößen über mehrere Sprachversionen hinweg.
Empfehlung
