
MT vs LLM vertaling: veilig & compliant kiezen in 2026
- 1 uur geleden
- 7 minuten om te lezen

Ondanks alle AI-hype is een LLM-gebaseerde vertaling niet automatisch veiliger of nauwkeuriger dan traditionele machinevertaling. Dat is een ongemakkelijke waarheid die professionals in de life sciences en juridische sector zich bewust moeten zijn. De keuze tussen MT en LLM vertaling raakt direct aan uw compliance-verplichtingen, uw aansprakelijkheidsrisico en de integriteit van gevoelige documenten. In dit artikel leert u precies waar de verschillen liggen, welke risico’s elke technologie met zich meebrengt, en hoe u een gefundeerde keuze maakt die aansluit bij de eisen van uw sector.
Inhoudsopgave
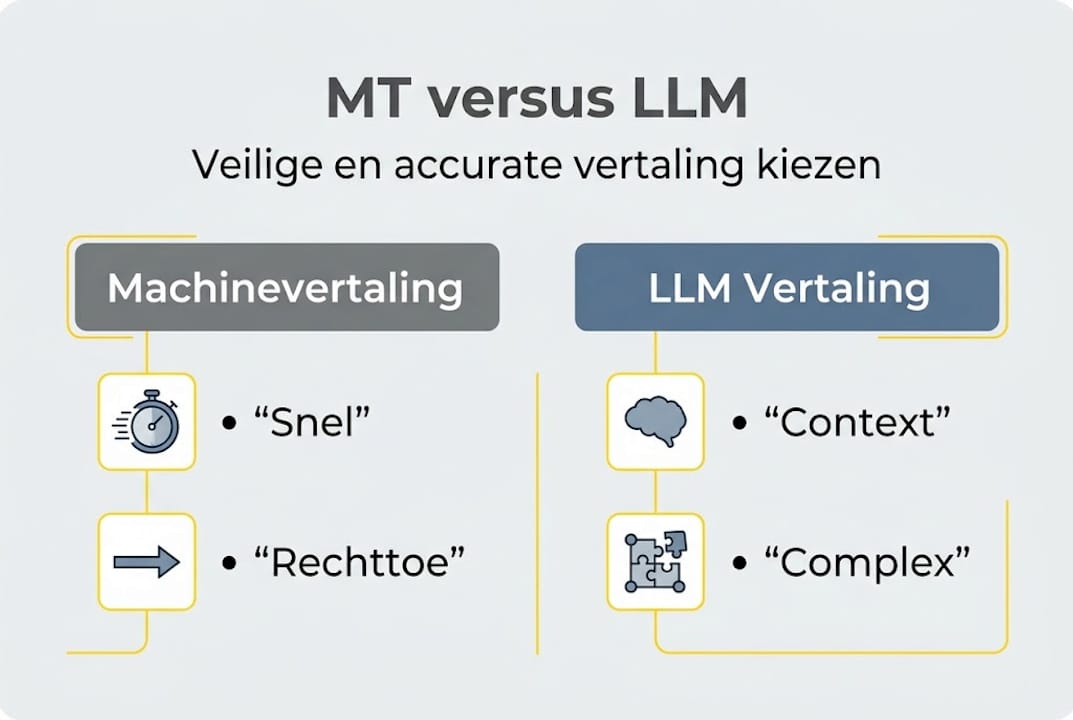
Wat is het verschil tussen machinevertaling en LLM-gebaseerde vertaling?
Veiligheid en compliance: privacy en AVG-risico’s bij MT en LLM
Kwaliteit en betrouwbaarheid: MT vs LLM in juridische en medische context
Praktische toepassing: wanneer kiest u voor MT, wanneer voor LLM (en hoe veilig)?
Ons inzicht: waarom de nuance tussen MT en LLM vertaling altijd kritisch blijft
Belangrijkste Inzichten
Punt | Details |
MT en LLM verschillen wezenlijk | MT is geschikt voor direct en overzichtelijk werk; LLM-modellen blinken uit bij complexe context en zeldzame talen. |
Data-veiligheid is niet vanzelfsprekend | Cloud-LLMs brengen serieuze compliance risico’s mee; on-premise of EU-hosting is vaak vereist. |
Menselijke controle blijft essentieel | Voor juridische en medische documenten voorkomt u fatale fouten alleen met menselijke eindcontrole. |
Technologiekeuze hangt af van context | Laat de use-case, gevoeligheid van data en regelgeving altijd leidend zijn bij de keuze van vertaalsysteem. |
Wat is het verschil tussen machinevertaling en LLM-gebaseerde vertaling?
Machinevertaling (MT) bestaat al tientallen jaren. De vroege varianten werkten op basis van vaste grammaticaregels en woordenboeken. Neurale machinevertaling (NMT) is de moderne opvolger: tools zoals DeepL of Google Translate gebruiken neurale netwerken die getraind zijn op enorme hoeveelheden taaldata. Ze leren patronen en produceren vloeiende vertalingen, maar begrijpen de tekst niet echt.
Een Large Language Model (LLM) werkt fundamenteel anders. Een LLM is een generatief AI-model dat getraind is om taal te begrijpen in context. Het kan instructies opvolgen, terminologie consequent toepassen en ambiguïteit oplossen op basis van de volledige documentcontext. Het verschil is niet gradueel, het is structureel.
Bij kritische keuzes mt vs llm in gereguleerde sectoren speelt dit onderscheid een doorslaggevende rol. Bekijk de vergelijking:
Kenmerk | Conventionele MT/NMT | LLM-gebaseerde vertaling |
Techniek | Neurale netwerken, patroonherkenning | Generatief model, contextbegrip |
Terminologiecontrole | Beperkt, inconsistent | Instructeerbaar, strikt afdwingbaar |
Omgang met ambiguïteit | Zwak, kiest meest voorkomende betekenis | Sterk, contextafhankelijk |
Aanpasbaarheid | Beperkt | Hoog, via fine-tuning en instructies |
Risico op hallucinaties | Aanwezig, moeilijk detecteerbaar | Aanwezig, maar beter beheersbaar |
Databeveiliging (publieke tools) | Hoog risico bij cloudgebruik | Hoog risico bij publieke LLMs |
Voor gereguleerde sectoren zijn de voordelen en nadelen van beide systemen concreet:
MT/NMT voordelen: Snel, goedkoop, bewezen voor generieke content
MT/NMT nadelen: Geen terminologiecontrole, hallucinaties, AVG-risico bij publieke tools
LLM voordelen: Contextbegrip, instructeerbaar, beter bij complexe semantiek en onderbedeelde talen
LLM nadelen: Hogere kosten, vereist zorgvuldige implementatie, niet automatisch compliant
Uit medisch onderzoek blijkt dat LLMs beter presteren bij onderbedeelde talen en semantisch complexe taken, terwijl traditionele MT op oppervlakkige metrics zoals BLEU soms nog hoger scoort. De keuze hangt dus sterk af van uw specifieke use-case en de vertaaltechnologie per sector die het beste past.
Veiligheid en compliance: privacy en AVG-risico’s bij MT en LLM
Na de technische uitleg rijst de hamvraag: hoe zit het met compliance en privacy in de praktijk? Dit is waar veel organisaties de fout ingaan.
De relevante wetgeving is omvangrijk. Voor Europese organisaties is de AVG (GDPR) leidend. In de gezondheidszorg geldt aanvullend HIPAA voor data die Amerikaanse patiënten betreft. De EU AI Act legt nieuwe verplichtingen op aan aanbieders van AI-systemen. En voor defensiegerelateerde of dual-use technologie speelt ITAR een rol. Elk van deze kaders stelt eisen aan waar data wordt opgeslagen, wie er toegang toe heeft en hoe lang data bewaard wordt.
Hier ligt een cruciaal misverstand: veel organisaties denken dat een LLM automatisch veiliger is dan publieke NMT. Dat klopt niet. LLMs brengen privacyrisico’s mee door cloudopslag, training op ingevoerde data en compliance-vereisten zoals een BAA (Business Associate Agreement) en GDPR-naleving. Een publieke LLM zoals een generieke chatbot is minstens zo riskant als DeepL voor vertrouwelijke documenten.
De datarisico’s per technologie op een rij:
Technologie | Datarisiconiveau | Belangrijkste risico |
Publieke NMT (bijv. DeepL, Google) | Hoog | Data verlaat EU, geen dataretentie-garantie |
Publieke LLM (bijv. generieke chatbots) | Hoog | Training op ingevoerde data, geen BAA |
On-premise MT | Laag tot middel | Afhankelijk van configuratie |
Private/on-premise LLM | Laag | Volledige controle, mits correct ingericht |
Concrete risico’s die u moet kennen:
Patiëntgegevens die via een publieke vertaaltool worden verwerkt, vormen een directe AVG-overtreding
Niet-gepubliceerde patenten die door een publieke NMT gaan, kunnen als openbaar beschouwd worden
Juridische stukken met vertrouwelijke cliëntinformatie mogen nooit via cloudtools worden verwerkt zonder verwerkersovereenkomst
On-premise implementatie is bij vertrouwelijke documenten geen luxe, maar een verplichting
“De veiligste vertaaloplossing is niet de slimste AI, maar de AI die uw data nooit verlaat.”
Dit is precies waarom precisie en compliance LLM alleen gegarandeerd kan worden via een gesloten, privaat systeem. AD VERBUM opereert uitsluitend op EU-servers zonder publieke cloudblootstelling, wat veilige AI-ondersteuning mogelijk maakt die ook compliance in juridische vertaling borgt.
Kwaliteit en betrouwbaarheid: MT vs LLM in juridische en medische context
Nu we de risico’s hebben geschetst, richten we ons op de feitelijke kwaliteit en betrouwbaarheid van beide systemen. Want een compliant vertaling die inhoudelijk onjuist is, lost niets op.
De meest gebruikte kwaliteitsmetrics zijn BLEU, CHR-F en METEOR. BLEU meet hoe sterk de machinevertaling overeenkomt met een referentievertaling op woordniveau. CHR-F kijkt naar karakterniveau-overeenkomsten. METEOR houdt ook rekening met synoniemen. Traditionele MT scoort op deze metrics vaak goed, omdat het dicht bij de brontekst blijft. Maar hoge BLEU-scores zeggen niets over semantische correctheid.
Research toont aan dat beide systemen beperkingen hebben: NMT worstelt met ambiguïteit en creatieve taalstructuren, terwijl LLMs juist uitdagingen kennen bij specifieke terminologie en talen met weinig trainingsdata. Geen van beide is foutloos.
In juridische en medische context zijn de specifieke uitdagingen:
Ambiguïteit: Het woord “treatment” betekent in een medische context “behandeling”, maar in een juridisch document “behandelingswijze” of zelfs “omgang”. NMT kiest de statistische meest voorkomende vertaling. Een LLM analyseert de context.
Negaties: NMT kan een negatie weglaten of omdraaien. “Niet-toxisch” wordt “toxisch”. Dit is in medische documentatie levensgevaarlijk.
Vaktermen: Consistente terminologie over honderden pagina’s is voor NMT vrijwel onmogelijk zonder een strikt opgelegde termbase.
De rol van menselijke kwaliteitscontrole is hier onmisbaar. Bij nmt vs llm compliance vertalingen geldt dat geen enkel systeem zonder vakinhoudelijke revisie geschikt is voor kritieke documenten.
Pro-tip: Gebruik bij medische of juridische vertalingen altijd een subject matter expert (SME) die zowel de bron als doeltaal beheerst én kennis heeft van het vakgebied. Taalvaardigheid alleen is onvoldoende. Zie ook hoe menselijke controle en toezicht de kwaliteit structureel verhoogt.
Praktische toepassing: wanneer kiest u voor MT, wanneer voor LLM (en hoe veilig)?
De logische vervolgstap: hoe maakt u nu de juiste en veilige keuze? Hier volgt een concreet stappenplan.
Bepaal de gevoeligheid van uw documenten. Bevat de content persoonsgegevens, patiëntdata, vertrouwelijke juridische informatie of ongepubliceerde technologie? Dan is publieke MT of publieke LLM direct uitgesloten.
Beoordeel uw compliance-verplichtingen. Welke wetgeving is van toepassing: AVG, HIPAA, EU AI Act, ITAR? Stel vast welke data-opslagvereisten gelden en of een verwerkersovereenkomst nodig is.
Analyseer de complexiteit van de content. Generieke, niet-gevoelige teksten kunnen met NMT worden verwerkt. Technische, juridische of medische documenten vereisen een LLM met terminologiecontrole én menselijke revisie.
Kies de juiste implementatievorm. On-premise LLM of een private cloud binnen de EU zijn de enige opties voor vertrouwelijke documenten. Fine-tuning op uw eigen termbase en stijlgids is geen optie maar noodzaak.
Integreer altijd menselijke controle. Onderzoek bevestigt dat menselijke controle cruciaal blijft bij kritieke dossiers, met een foutenrisico van tot 6% bij medische en juridische vertalingen zonder revisie.
De combinatie van AI en menselijke expertise is niet een compromis, het is de enige verantwoorde aanpak. Bij het kiezen van de juiste vertaaldienst is dit het eerste criterium waarop u moet selecteren. De impact van neurale MT op compliance is te groot om over het hoofd te zien.
Pro-tip: Vraag elke vertaaldienst expliciet naar hun data-verwerkingslocatie, of ze een ISO 27001-certificering hebben en hoe terminologieconsistentie technisch wordt afgedwongen. Leveranciers die hier vaag over zijn, voldoen waarschijnlijk niet aan uw compliance-eisen.
Ons inzicht: waarom de nuance tussen MT en LLM vertaling altijd kritisch blijft
Wij zien in de praktijk één terugkerend patroon: organisaties die blindelings overstappen op LLM-vertalingen, ervan overtuigd dat “nieuwer” automatisch “beter en veiliger” betekent. Dat is een gevaarlijke aanname.
Een LLM zonder private implementatie, zonder fine-tuning op uw termbase en zonder SME-revisie is niet superieur aan een goed geconfigureerde MT-oplossing. Het is anders, en in sommige opzichten riskanter, omdat de output vloeiender klinkt en fouten daardoor moeilijker te detecteren zijn. Vloeiend klinkende tekst wekt vertrouwen, ook als de inhoud onjuist is.
Waar menselijke expertise onmisbaar blijft, is precies op het snijvlak van vakinhoud en taal. Een AI begrijpt niet wat de juridische consequentie is van een verkeerd vertaald contractbeding. Een medisch linguïst wel. De compliance-fouten die wij het vaakst zien, zijn niet technisch van aard maar organisatorisch: geen verwerkersovereenkomst, geen termbase, geen SME in het proces. Lees meer over AI in juridische vertalingen en hoe u deze valkuilen vermijdt.
Veilig vertalen in uw sector? Ontdek onze aanpak
Wilt u deze kennis toepassen in de praktijk? AD VERBUM combineert een proprietary LLM-ecosysteem op EU-servers met een netwerk van meer dan 3.500 vakinhoudelijke linguïsten voor een volledig AI+HUMAN werkproces. Uw data verlaat nooit onze beveiligde infrastructuur, en terminologieconsistentie wordt technisch afgedwongen via uw eigen termbase en stijlgids.
Of u nu klinische documentatie, patentdossiers of juridische contracten laat vertalen: onze professionele vertaaloplossingen zijn gebouwd voor sectoren waar een fout geen optie is. Bekijk onze AI+human translations en vraag een adviesgesprek aan om te bespreken hoe wij uw specifieke compliance-eisen invullen.
Veelgestelde vragen over MT vs LLM vertaling
Welke technologie is veiliger voor vertrouwelijke juridische documenten?
Alleen een on-premise LLM of een strikt geconfigureerde MT-oplossing met dataopslag binnen de EU biedt voldoende veiligheid, mits aangevuld met een verwerkersovereenkomst en naleving van GDPR en BAA.
Presteert LLM altijd beter qua kwaliteit dan traditionele MT?
Nee. Op oppervlakkige metrics zoals BLEU scoort MT vaak hoger; LLMs zijn sterker bij semantisch complexe taken en onderbedeelde talen, maar niet universeel superieur.
Blijft menselijke controle altijd nodig voor kritieke vertalingen?
Ja, zonder uitzondering. Voor juridische en medische dossiers is SME-revisie essentieel omdat menselijk toezicht fouten voorkomt die anders tot serieuze aansprakelijkheid leiden.
Welke compliance-wetgeving is relevant bij MT/LLM gebruik?
De belangrijkste kaders zijn GDPR, HIPAA, de EU AI Act en mogelijk ITAR, afhankelijk van uw sector en de locatie van dataopslag.
Aanbeveling