
Datensouveränität in Sprachdienstleistungen für regulierte Branchen
- 23. März
- 8 Min. Lesezeit

Wenn ein Pharmaunternehmen klinische Studiendaten zur Übersetzung an einen Dienstleister sendet, stellt sich eine kritische Frage: Wo werden diese sensiblen Patientendaten verarbeitet? Viele Fachkräfte glauben, moderne Cloud-Übersetzungen seien automatisch sicher. Die Realität ist komplexer. In regulierten Branchen wie Medizin, Recht und Technik entscheidet die Datensouveränität über Compliance oder Haftungsrisiko. Dieser Leitfaden zeigt Ihnen, wie Sie Datensouveränität im Übersetzungsprozess sicherstellen und welche technologischen Lösungen existieren, um rechtliche Anforderungen zu erfüllen.
Inhaltsverzeichnis
Die herausforderungen der datensouveränität in sprachdienstleistungen bei regulierten branchen
Technologische ansätze zur gewährleistung der datensouveränität
Regulatorische differenzen und branchenspezifische anforderungen
Praktische umsetzung und beste praxis für datensouveränität in sprachdienstleistungen
Wie AD VERBUM bei datensouveränität in sprachdienstleistungen unterstützt
Häufig gestellte fragen zur datensouveränität in sprachdienstleistungen
Wichtige Erkenntnisse
Punkt | Details |
EU Rechtskonformität sichern | In regulierten Bereichen dürfen sensible Patientendaten ausschließlich innerhalb der EU verarbeitet werden und US Cloud Dienste sind zu vermeiden. |
Open Source LLMs nutzen | Offene Modelle ermöglichen lokale Feinabstimmung und volle Kontrolle über Daten und Inferenzprozesse ohne Verlassen der eigenen Infrastruktur. |
Hybride Modelle mit Aufsicht | Kombinieren Sie maschinelle Übersetzung mit menschlicher Kontrolle, um Genauigkeit und Compliance zu erhöhen. |
Branchenspezifische Anforderungen beachten | Medizin PHI, Rechtsdokumente PII und technische Unterlagen erfordern jeweils spezifische Lokalisierung und Datenschutzmaßnahmen. |
Datenfluss offen dokumentieren | Bitten Sie um eine detaillierte Datenflussdokumentation des Dienstleisters, die jeden Verarbeitungsschritt von der Übermittlung bis zur Rücklieferung abbildet. |
Wichtigste erkenntnisse
Aspekt | Kernaussage |
Regulatorische Basis | Datensouveränität erfordert EU-interne Verarbeitung nach DSGVO Art. 9 und HIPAA, US-Clouds sind problematisch |
Technologische Lösung | Open-Source LLMs wie Teuken-7B ermöglichen lokale Anpassung bei voller DSGVO-Konformität |
Qualitätssicherung | Hybride AI+HUMAN Modelle kombinieren KI-Effizienz mit menschlicher Fachkontrolle für regulierte Dokumente |
Branchenspezifik | Medizin verlangt PHI-Schutz, Recht benötigt PII-Sicherheit, Technik fordert IP-Wahrung |
Praktische Umsetzung | On-Premise Hosting, transparente Dokumentation und regelmäßige Audits sichern Compliance |
Die herausforderungen der datensouveränität in sprachdienstleistungen bei regulierten branchen
Datenschutz in Übersetzungsprozessen ist keine theoretische Übung. In regulierten Sektoren wie Medizin, Recht und Technik erfordert Datensouveränität EU-interne Verarbeitung, explizite Einwilligungen und strikte Vermeidung von US-Cloud-Diensten. Die DSGVO Artikel 9 kategorisiert Gesundheitsdaten als besonders schützenswert. HIPAA verlangt in den USA vergleichbare Sicherheitsmaßnahmen. Beide Regelwerke definieren präzise, wo und wie personenbezogene Daten verarbeitet werden dürfen.
Die Komplexität steigt, wenn Übersetzungsdienstleister externe Technologien nutzen. Viele populäre maschinelle Übersetzungsdienste operieren auf US-Servern oder nutzen öffentliche Cloud-Infrastrukturen. Das schafft einen direkten Konflikt: Sensible Patientenakten, unveröffentlichte Patentanmeldungen oder vertrauliche Vertragsklauseln dürfen nicht in Systeme gelangen, die außerhalb der EU-Rechtshoheit liegen. Der bloße Upload eines Dokuments kann bereits einen Rechtsverstoß darstellen.
Branchenspezifische Besonderheiten verschärfen die Anforderungen:
Medizinische Dokumentation: Klinische Studienergebnisse, Beipackzettel und Patientenfragebögen enthalten Protected Health Information (PHI), die strengste Lokalisierung verlangt
Rechtsdokumente: Verträge, Gerichtsakten und Due-Diligence-Materialien beinhalten personenbezogene Daten (PII), die Mandantenvertraulichkeit erfordern
Technische Unterlagen: Konstruktionspläne, Sicherheitsdatenblätter und Betriebsanleitungen enthalten geistiges Eigentum, dessen Abfluss Wettbewerbsvorteile gefährdet
Transparenz wird zum Compliance-Faktor. Sie müssen jederzeit nachweisen können, welche Systeme Ihre Daten verarbeiten, wer Zugriff hat und wo Server physisch stehen. Vage Zusicherungen von Dienstleistern reichen nicht. Verträge müssen technische Details spezifizieren: Serverstandorte, Verschlüsselungsstandards, Zugriffskontrollen und Löschfristen.
Profi-Tipp: Fordern Sie von Übersetzungsdienstleistern eine detaillierte Datenfluss-Dokumentation an, die jeden Verarbeitungsschritt von der Dokumentenübermittlung bis zur Rücklieferung abbildet. Diese Transparenz ist bei Audits unverzichtbar.
Technologische ansätze zur gewährleistung der datensouveränität
Moderne Sprachmodelle revolutionieren Übersetzungen, doch nicht alle Technologien sind für regulierte Branchen geeignet. Die Wahl zwischen proprietären und Open-Source Large Language Models (LLMs) hat direkten Einfluss auf Ihre Datensouveränität. Proprietäre Modelle wie GPT-4 oder Claude bieten beeindruckende Leistung, operieren aber typischerweise als Cloud-Dienst. Ihre Daten durchlaufen externe Server, oft in US-Rechtsräumen.
Open-Source LLMs ändern diese Dynamik fundamental. Modelle wie Llama, Mistral oder europäische Sprachmodelle wie Teuken-7B ermöglichen lokale Feinabstimmung für DSGVO-Konformität in regulierten Branchen. Sie können diese Modelle auf eigener Infrastruktur betreiben, ohne dass Daten Ihr Rechenzentrum verlassen. Die vollständige Kontrolle über Modellparameter, Trainingsdaten und Inferenz-Prozesse liegt bei Ihnen.
Vergleich führender europäischer LLMs für Übersetzungen:
Modell | Herkunft | Parameter | Datenschutz-Vorteil | Übersetzungsqualität |
Teuken-7B | Finnland | 7 Milliarden | EU-Server, vollständige Anpassbarkeit | Exzellent für nordeuropäische Sprachen |
BLOOM | Frankreich | 176 Milliarden | Open-Source, lokales Hosting möglich | Sehr gut für mehrsprachige Szenarien |
LeoLM | Deutschland | 13 Milliarden | Deutsche Sprachoptimierung, EU-Fokus | Hervorragend für Deutsch-Englisch |
Die technische Umsetzung erfordert Infrastruktur-Planung. On-Premise Hosting großer Sprachmodelle verlangt substantielle Rechenkapazität. Ein 7-Milliarden-Parameter-Modell benötigt mindestens 16 GB GPU-Speicher für Inferenz, größere Modelle entsprechend mehr. Für Unternehmen ohne eigene KI-Infrastruktur bieten sich spezialisierte Dienstleister an, die proprietäre Übersetzungs-KI auf EU-Servern betreiben.

AD VERBUM setzt auf ein proprietäres LLM-Ökosystem, das ausschließlich auf EU-Servern läuft. Im Gegensatz zu öffentlichen NMT-Tools wie DeepL oder Google Translate, die Daten durch externe Systeme leiten, bleibt bei AD VERBUM jedes Dokument in einer geschlossenen, ISO 27001-zertifizierten Umgebung. Das eliminiert Datenlecks und erfüllt strengste Compliance-Anforderungen.
Die Integration von Translation Memories ™ und Terminologiedatenbanken (TB) verstärkt die Kontrolle. Sie definieren exakt, welche Begriffe wie übersetzt werden. Ein LLM, das auf Ihre Unternehmens-TM trainiert ist, reproduziert konsistent Ihre etablierte Terminologie. Das verhindert Abweichungen, die bei generischen Übersetzungsdiensten auftreten.
Profi-Tipp: Evaluieren Sie Open-Source LLMs zunächst mit nicht-sensiblen Testdokumenten. Messen Sie Übersetzungsqualität, Verarbeitungsgeschwindigkeit und Ressourcenbedarf, bevor Sie kritische Daten migrieren. Dieser Proof-of-Concept minimiert Implementierungsrisiken.
Regulatorische differenzen und branchenspezifische anforderungen
Jede regulierte Branche definiert Datensouveränität unterschiedlich. Was in der Technikdokumentation ausreicht, erfüllt medizinische Standards möglicherweise nicht. Diese Nuancen zu verstehen, verhindert kostspielige Compliance-Verstöße.
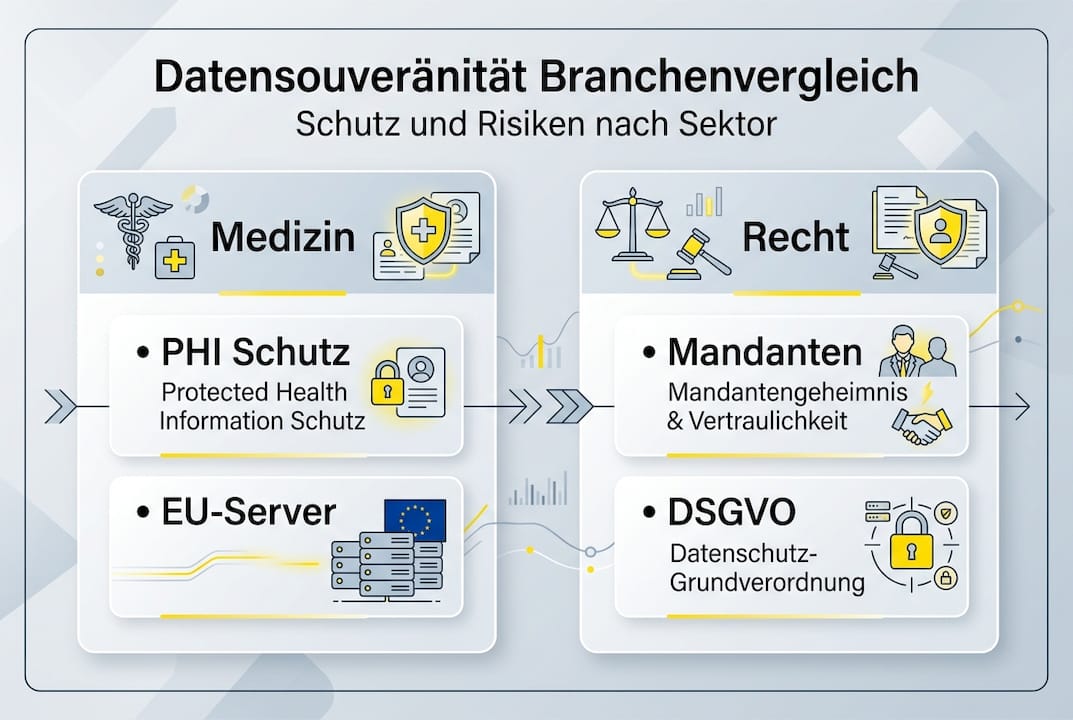
Medizinischer Sektor: Protected Health Information (PHI) unterliegt den strengsten Lokalisierungsanforderungen. Gesundheitsdaten erfordern souveräne grenzüberschreitende Übertragung mit expliziten Patienteneinwilligungen. HIPAA in den USA und DSGVO in Europa verlangen End-to-End-Verschlüsselung, Zugriffsprotokolle und sofortige Löschbarkeit. Klinische Studien, die mehrere Länder umfassen, müssen für jede Jurisdiktion separate Datenschutzprotokolle implementieren. Telemedizin verschärft dies: Ein Arzt in Deutschland, der einen Patienten in Frankreich behandelt und Befunde zur Übersetzung nach Spanien sendet, navigiert drei Rechtssysteme.
Rechtlicher Sektor: Mandantenvertraulichkeit ist absolut. Verträge, Gerichtsakten und M&A-Dokumente enthalten personenbezogene Daten und Geschäftsgeheimnisse. Anwaltskanzleien tragen Haftungsrisiken, wenn vertrauliche Informationen durch unsichere Übersetzungsprozesse kompromittiert werden. Der Konflikt zwischen dem US Cloud Act und europäischer DSGVO ist hier besonders problematisch: US-Behörden können theoretisch auf Daten zugreifen, die auf US-Servern liegen, selbst wenn diese EU-Bürger betreffen.
Technischer Sektor: Geistiges Eigentum definiert Wettbewerbsvorteile. Konstruktionspläne, Patentanmeldungen vor Veröffentlichung und proprietäre Fertigungsprozesse dürfen nicht in öffentliche Systeme gelangen. Ein einziger Upload einer unveröffentlichten Patentzeichnung in ein Cloud-basiertes Übersetzungstool kann Patentansprüche gefährden, da öffentliche Offenlegung die Neuheit zerstört.
Kritische Szenarien nach Branche:
Pharma-Klinikstudien: Patientendaten aus 15 EU-Ländern müssen zentral übersetzt werden, ohne dass Daten US-Server berühren
Internationale Fusionen: Due-Diligence-Dokumente enthalten sensible Finanzdaten, die unter Geheimhaltungsvereinbarungen stehen
Medizinprodukte-Zulassung: Technische Dokumentation muss simultan in 27 EU-Sprachen übersetzt werden, mit vollständiger Rückverfolgbarkeit jeder Änderung
Grenzüberschreitende Rechtsfälle: Beweismittel müssen übersetzt werden, ohne dass Dritte Zugriff erhalten
Datenklassifizierung nach Schutzbedarf:
Datentyp | Regulierung | Lokalisierungsanforderung | Übersetzungsrisiko |
PHI (Gesundheit) | HIPAA, DSGVO Art. 9 | Strengste EU-interne Verarbeitung | Hoch: Patientenidentifikation |
PII (Recht) | DSGVO, nationale Datenschutzgesetze | EU-intern, Mandanteneinwilligung | Mittel: Vertraulichkeitsbruch |
IP (Technik) | Patentrecht, Geschäftsgeheimnisse | Kontrollierte Umgebung | Hoch: Wettbewerbsverlust |
Finanzdaten | MiFID II, nationale Finanzaufsicht | EU-intern, Verschlüsselung | Mittel: Marktmanipulation |
Die Lösung liegt in spezialisierten Dienstleistern, die HIPAA-konforme Übersetzung und DSGVO-konforme Prozesse als Standard implementieren, nicht als Zusatzleistung.
Praktische umsetzung und beste praxis für datensouveränität in sprachdienstleistungen
Theorie wird wertlos ohne Umsetzung. Diese konkreten Maßnahmen transformieren regulatorische Anforderungen in operative Realität.
On-Premise Lösungen eliminieren externe Datenzugriffe vollständig. Bundesverwaltungen hosten LLMs on-premise, fokussieren auf Wechselmöglichkeit und direkten Einfluss, wobei Risiken bei reiner Arbeitsunterstützung überschaubar bleiben. Dieser Ansatz funktioniert für Organisationen mit eigener IT-Infrastruktur. Sie installieren Open-Source LLMs auf internen Servern, integrieren diese mit bestehenden Translation-Memory-Systemen und kontrollieren jeden Aspekt der Datenverarbeitung. Der Nachteil: hohe Initialkosten und laufender Wartungsaufwand.
Für Unternehmen ohne KI-Expertise bieten spezialisierte Dienstleister eine Alternative. AD VERBUM operiert ein geschlossenes AI+HUMAN Ökosystem auf EU-Servern. Jedes Dokument durchläuft einen kontrollierten Workflow: proprietäre LLM-Verarbeitung, gefolgt von Fachexperten-Validierung. Medizinische Übersetzungen werden von Linguisten mit medizinischem Hintergrund geprüft, rechtliche von Juristen, technische von Ingenieuren. Diese zweistufige Qualitätssicherung kombiniert KI-Effizienz mit menschlicher Präzision.
Implementierungs-Checkliste für datensouveräne Übersetzungen:
Dokumentieren Sie vollständige Datenflüsse von Quelldokument bis Endlieferung, inklusive aller Zwischensysteme
Verifizieren Sie physische Serverstandorte und rechtliche Zuständigkeit jedes beteiligten Dienstleisters
Implementieren Sie End-to-End-Verschlüsselung für Dokumentenübertragung und Speicherung
Etablieren Sie Zugriffskontrollen mit Zwei-Faktor-Authentifizierung für alle Übersetzungsplattformen
Definieren Sie Aufbewahrungsfristen und automatisierte Löschprozesse nach Projektabschluss
Schulen Sie Übersetzungsteams in Datenschutzprotokollen und Incident-Response-Verfahren
Führen Sie quartalsweise Audits durch, um Compliance kontinuierlich zu verifizieren
Hybrid Human-AI Modelle adressieren die Grenzen reiner Automatisierung. KI übersetzt schnell und konsistent, aber versteht Kontext begrenzt. Ein medizinisches LLM könnte “Hypertonie” technisch korrekt übersetzen, aber den klinischen Kontext missverstehen, der eine spezifischere Formulierung erfordert. Menschliche Experten fangen diese Nuancen ab. Bei AD VERBUM validiert ein Subject Matter Expert (SME) jede KI-generierte Übersetzung, bevor sie den Kunden erreicht.
Einwilligungs- und Nutzungsdokumentation wird oft vernachlässigt, ist aber rechtlich zwingend. Jede Verarbeitung personenbezogener Daten erfordert dokumentierte Rechtsgrundlage. Für Übersetzungen bedeutet das: schriftliche Einwilligung der betroffenen Person oder legitimes Interesse des Verantwortlichen. Speichern Sie diese Nachweise revisionssicher. Bei Audits müssen Sie belegen können, dass Sie berechtigt waren, spezifische Daten zu verarbeiten.
Profi-Tipp: Implementieren Sie ein Klassifizierungssystem für eingehende Dokumente. Markieren Sie automatisch Dateien mit PHI, PII oder IP, um sicherzustellen, dass diese nur über datensouveräne Kanäle verarbeitet werden. Ein versehentlicher Upload sensibler Daten in ein öffentliches System wird so technisch verhindert.
Regelmäßige Audits schließen den Kreis. Compliance ist kein einmaliges Projekt, sondern kontinuierlicher Prozess. Überprüfen Sie vierteljährlich: Werden alle Übersetzungen über genehmigte Systeme abgewickelt? Sind Zugriffsrechte aktuell? Funktionieren automatisierte Löschprozesse? Dokumentieren Sie Audit-Ergebnisse und beheben Sie Abweichungen sofort. Diese Nachweise sind bei regulatorischen Inspektionen unverzichtbar.
Wie AD VERBUM bei datensouveränität in sprachdienstleistungen unterstützt
Datenschutzkonforme Übersetzung erfordert mehr als technische Lösungen. Sie brauchen einen Partner, der regulatorische Komplexität versteht und operative Exzellenz liefert. AD VERBUM kombiniert über 25 Jahre Branchenerfahrung mit einem proprietären AI+HUMAN Workflow, der ausschließlich auf EU-Servern operiert.

Unser geschlossenes LLM-Ökosystem verarbeitet Ihre professionellen Übersetzungen ohne externe Datenzugriffe. Im Gegensatz zu öffentlichen NMT-Diensten verlassen Ihre Dokumente nie unsere ISO 27001-zertifizierte Infrastruktur. Jede Übersetzung durchläuft Fachexperten-Validierung: Mediziner prüfen Life Sciences Übersetzungen, Juristen rechtliche Dokumente, Ingenieure technische Unterlagen. Diese Kombination aus KI-Geschwindigkeit und menschlicher Präzision erfüllt strengste Compliance-Anforderungen.
Wir integrieren Ihre Translation Memories und Terminologiedatenbanken direkt in unseren Workflow. Das garantiert konsistente Terminologie über tausende Seiten hinweg. Für mehrsprachige Dokumentation bieten wir vollständige Lokalisierung, von der Übersetzung bis zum finalen Layout. Ihre Datensouveränität bleibt dabei jederzeit gewahrt. Kontaktieren Sie uns für eine individuelle Beratung zu Ihren spezifischen Compliance-Anforderungen.
Häufig gestellte fragen zur datensouveränität in sprachdienstleistungen
Was bedeutet datensouveränität konkret für übersetzungsprojekte?
Datensouveränität bedeutet vollständige Kontrolle über Speicherort, Verarbeitung und Zugriff auf Ihre Daten während des gesamten Übersetzungsprozesses. Für regulierte Branchen heißt das: Dokumente dürfen nur auf Servern innerhalb der EU verarbeitet werden, externe Zugriffe müssen ausgeschlossen sein und Sie müssen jederzeit nachweisen können, wo Ihre Daten liegen. Praktisch erfordert dies Dienstleister mit eigener EU-Infrastruktur statt Cloud-basierter Lösungen.
Warum sind öffentliche übersetzungstools wie DeepL für regulierte branchen problematisch?
Öffentliche Tools verarbeiten Daten auf externen Servern, oft außerhalb der EU. Der Upload sensibler Patientendaten oder vertraulicher Verträge in solche Systeme verletzt DSGVO und HIPAA. Zusätzlich speichern viele Dienste Eingaben zur Modellverbesserung, was Ihre Daten potentiell anderen Nutzern aussetzt. Für PHI, PII oder geistiges Eigentum sind diese Risiken inakzeptabel.
Welche technischen mindestanforderungen gelten für dsgvo-konforme übersetzungen?
Mindestanforderungen umfassen EU-basierte Serverstandorte, End-to-End-Verschlüsselung bei Übertragung und Speicherung, dokumentierte Zugriffskontrollen und automatisierte Löschprozesse nach Projektende. Zusätzlich benötigen Sie Verträge zur Auftragsverarbeitung nach Art. 28 DSGVO, die technische und organisatorische Maßnahmen detailliert spezifizieren. Regelmäßige Audits verifizieren die Einhaltung dieser Standards.
Wie unterscheidet sich AD VERBUM’s ansatz von traditionellen übersetzungsagenturen?
AD VERBUM betreibt ein proprietäres LLM-Ökosystem auf EU-Servern, statt externe Cloud-Dienste zu nutzen. Unser AI+HUMAN Workflow kombiniert KI-Effizienz mit Fachexperten-Validierung durch über 3.500 Subject Matter Experts. Im Gegensatz zu Agenturen, die Projekte an Freelancer outsourcen, bleibt bei uns die gesamte Verarbeitungskette in einer geschlossenen, ISO 27001-zertifizierten Umgebung. Das eliminiert Datenlecks und erfüllt strengste Compliance-Standards.
Welche rolle spielen translation memories bei datensouveränität?
Translation Memories ™ sind Datenbanken bereits übersetzter Segmente, die Konsistenz und Effizienz erhöhen. Für Datensouveränität sind sie kritisch, weil sie oft sensible Terminologie und Kontextinformationen enthalten. Diese TMs müssen genauso geschützt werden wie die Originaldokumente. AD VERBUM integriert Ihre TMs direkt in unser geschlossenes System, sodass auch diese Assets nie externe Server berühren. Das bewahrt sowohl Ihre Daten als auch Ihr etabliertes Übersetzungs-Know-how.
Wie bereite ich mein unternehmen auf audits zur datensouveränität vor?
Dokumentieren Sie vollständige Datenflüsse für alle Übersetzungsprozesse, inklusive Dienstleisterverträge, Serverstandorte und Sicherheitsmaßnahmen. Sammeln Sie Nachweise für Einwilligungen oder legitime Interessen bei jeder Datenverarbeitung. Führen Sie interne Audits durch, um Lücken proaktiv zu identifizieren. Stellen Sie sicher, dass Ihr Übersetzungsdienstleister aktuelle ISO-Zertifizierungen und DSGVO-Compliance nachweisen kann. Diese Vorbereitung macht regulatorische Inspektionen zu Routineverfahren statt zu Stresssituationen.
Empfehlung