
Sådan sikrer du kvalitet med AI+human workflow
- 31. mar.
- 8 min læsning

En enkelt fejloversættelse i en medicinindlægsseddel kan koste millioner i bøder og forsinke produktgodkendelser i måneder. Når fejloversættelser i højrisko-brancher giver >60% regulatoriske fejl, står beslutningstagere overfor et dilemma: Hvordan udnytter man AI’s hastighed uden at kompromittere den nøjagtighed, som compliance kræver? Svaret ligger i et struktureret AI+HUMAN workflow, der kombinerer maskinens effektivitet med menneskelig ekspertise. Denne artikel guider dig trin for trin gennem implementeringen af et kvalitetssikret oversættelsesworkflow, der opfylder både regulatoriske krav og forretningsmæssige deadlines.
Indholdsfortegnelse
Vigtigste Pointer
Punkt | Detaljer |
AI+human er nødvendigt | AI alene kan ikke opfylde compliance- eller nuanceringskrav i regulerede brancher. |
Risikobaseret workflow | Brug altid flere kontroltrin og menneskelig validering for kritiske dokumenter. |
Vælg rigtige værktøjer | DQF, MQM, og uddannede fagspecialister sikrer konsistent høj kvalitet. |
Løbende optimering | Feedback og lærerunderstøttelse forbedrer AI-systemer over tid uden at gå på kompromis med compliance. |
Hvad kræver kvalitetssikring i risikofyldte brancher?
I livsvidenskab, jura, finans og produktion er oversættelse ikke blot en sproglig øvelse. Det er en compliance-forpligtelse. Højrisiko-brancher kræver menneskelig kvalitetssikring på grund af både lovgivning og AI’s iboende begrænsninger. EU AI Act klassificerer oversættelsessystemer i medicinske og juridiske sammenhænge som højrisikoteknologi, hvilket betyder obligatorisk menneskelig validering. FDA og EMA stiller lignende krav til dokumentation, der indgår i godkendelsesprocesser.
AI-systemer fejler konsekvent på fire kritiske områder: kontekstforståelse, idiomatiske udtryk, lavressourcesprog og tvetydighed. En maskinoversættelse kan perfekt gengive ordene “kontraindikation” og “indikation”, men fejlfortolke hvilken der gælder i en given sætning. I et juridisk dokument kan forskellen mellem “skal” og “bør” afgøre kontraktens gyldighed. I finansielle aftaler kan en forkert oversættelse af “liability” som “ansvar” i stedet for “forpligtelse” skabe juridiske huller.
“En fejloversættelse i en klinisk prøveprotokol kostede et farmaceutisk selskab 18 måneders forsinkelse og €4,2 millioner i genindsendelses- og testomkostninger.”
Disse konsekvenser forklarer, hvorfor ISO 18587 standarden for post-editing af maskinoversættelse er blevet obligatorisk i regulerede brancher. Standarden kræver dokumenteret menneskelig gennemgang, terminologisk konsistens og sporbarhed. Edge cases illustrerer problemet: Når AI oversætter “patient experienced adverse events” til “patienten oplevede uønskede hændelser” i stedet for det korrekte medicinske term “bivirkninger”, kan det påvirke farmakovigilans-rapportering.
For at navigere disse udfordringer skal virksomheder implementere et workflow for kvalitetssikring i juridisk oversættelse, der integrerer både teknologi og ekspertise. Kvalitetssikring af regulatoriske AI+human oversættelser kræver systematisk tilgang med klare ansvarsområder og valideringspunkter. Internationale best practices, som beskrevet i QA pipelines for compliance, viser at hybrid-workflows reducerer fejlrater med 73% sammenlignet med ren maskinoversættelse.
Kritiske fejltyper der kræver menneskelig validering:
Negationsfejl: “non-toxic” bliver til “toxic”
Doserings-tvetydighed: “1-2 tabletter” vs “1 til 2 tabletter”
Juridisk præcision: “may” vs “shall” vs “must”
Kulturel kontekst: Datoformater, måleenheder, valutaer
Terminologisk konsistens: Samme term på tværs af 500+ siders dokumentation
Når vi forstår hvorfor kvalitetssikring er kritisk, skal vi se på hvilke konkrete systemer og værktøjer der muliggør den optimale workflow.
Forudsætninger og nøgleværktøjer for et solidt AI+human workflow
Et effektivt AI+HUMAN workflow hviler på tre søjler: teknologisk kapacitet, menneskelig ekspertise og systematisk dokumentation. Hver komponent skal opfylde specifikke kvalitetskrav for at sikre compliance.
AI-motoren skal dokumentere sin performance gennem BLEU-score, træningsdata og sprogretninger. En BLEU-score på minimum 40 er acceptabel for generel tekst, men medicinske og juridiske domæner kræver 55+. Motoren skal være trænet på domænespecifikke data, ikke generisk internetindhold. For farmaceutiske oversættelser betyder det træning på EMA-guidelines, IDMP-standarder og medicinsk terminologi. Sprogretningen påvirker kvaliteten markant: Oversættelse fra engelsk til dansk (L1→L2) kræver typisk mere omfattende post-editing end omvendt.
Professionelt tip: Test altid AI-motorens performance på jeres egne tidligere oversættelser før implementering. Sammenlign output med godkendte versioner for at identificere systematiske fejlmønstre.
Human-in-the-loop komponenten kræver fagspecialister med både sproglig og domæneekspertise. En post-editor til medicinske tekster skal ideelt set have baggrund som farmaceut, læge eller bioingeniør kombineret med oversætteruddannelse. ISO 18587 specificerer kompetencekrav: Forståelse for både kilde- og målsprog, domæneviden, kendskab til maskinoversættelsens begrænsninger og erfaring med CAT-værktøjer.
Værktøj | Funktion | Compliance-værdi |
Termbase (TB) | Sikrer konsistent terminologi på tværs af projekter | Obligatorisk for MDR, FDA submissions |
Translation Memory ™ | Genbruger godkendte oversættelser | Reducerer validerings-tid med 40% |
QA-moduler (MQM/DQF) | Automatisk fejldetektion og scoring | Dokumenterer kvalitetsniveau objektivt |
Audit trail system | Sporer alle ændringer og beslutninger | Lovkrav under EU AI Act |
Feedback-loop platform | Forbedrer AI-output baseret på korrektioner | Kontinuerlig kvalitetsforbedring |
Software-økosystemet skal integrere disse komponenter. DeepL Pro eller lignende NMT-systemer leverer basis-output, men skal kombineres med DQF (Dynamic Quality Framework) til kvalitetsmåling og MQM (Multidimensional Quality Metrics) til fejlkategorisering. ESAAI (European Society for Artificial Intelligence) anbefalinger for audit trails sikrer sporbarhed.
Dokumentation er ikke valgfri. Hver oversættelse skal ledsages af metadata: Hvilken AI-version blev brugt? Hvem udførte post-editing? Hvilke terminologiske beslutninger blev truffet? Denne dokumentation bliver jeres forsvar ved audits. ISO 18587 kræver, at post-editors logger deres arbejde, herunder tidsforbruget og typen af rettelser.
For at implementere disse værktøjer effektivt, følg vores ai+human sprogworkflow guide. Virksomheder i særligt følsomme sektorer bør også konsultere vores guide til datasikre AI+human workflows, der adresserer GDPR og datasuverænitet.
Nu hvor du kender forudsætningerne, er næste skridt at følge selve workflowet trin for trin.
Trin-for-trin: Workflow for AI+human kvalitetssikring
Et robust AI+HUMAN workflow består af fem sekventielle faser, hver med specifikke leverancer og kvalitetskontroller.
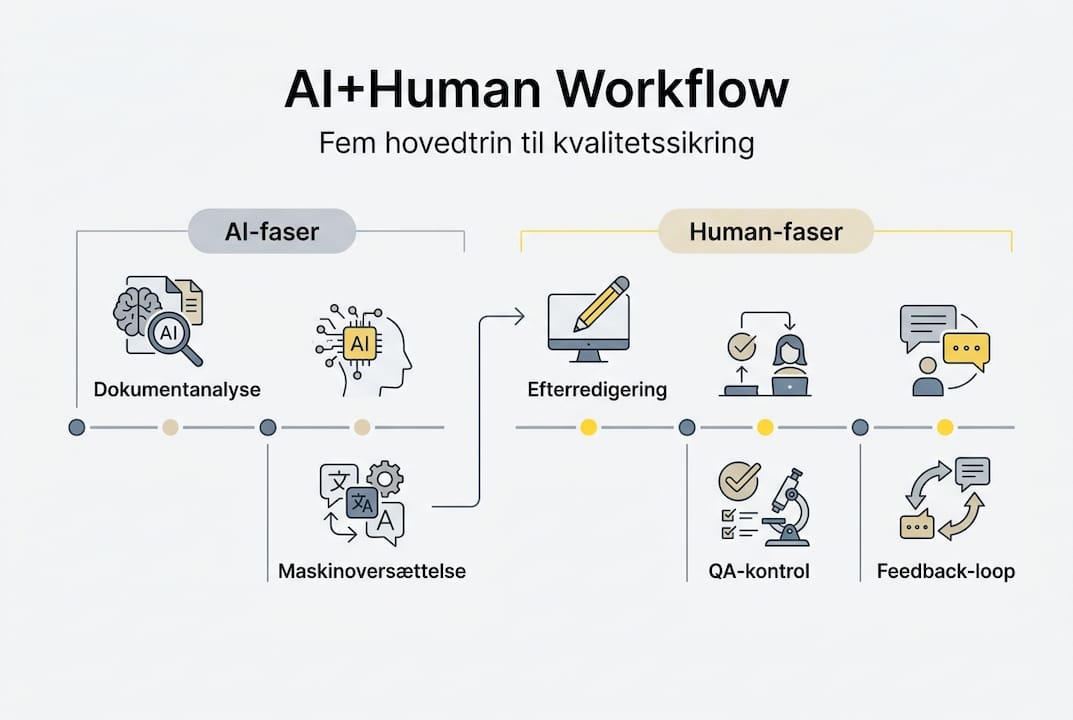
1. Foranalyse og risikovurdering
Før oversættelsen påbegyndes, skal dokumentet klassificeres efter risikoniveau. Høj risiko omfatter: Medicinindlægssedler, kliniske prøveprotokoller, patentansøgninger, finansielle prospekter og sikkerhedsdatablad. Medium risiko: Marketingmateriale til regulerede produkter, interne procedurer, træningsmanual. Lav risiko: Generel korrespondance, nyhedsbreve.
Risikovurderingen bestemmer workflowets stringens. Høj risiko kræver dual review (to uafhængige post-editors), medium risiko kræver single review plus QA-check, lav risiko kan klares med light post-editing. Compliance-checks identificerer relevante standarder: Er dokumentet omfattet af MDR? Skal det indsendes til FDA? Kræver det notarbekræftelse?
2. Maskinoversættelse
AI-motoren genererer bulk output baseret på domænespecifik konfiguration. For medicinske tekster aktiveres farmaceutisk termbase og tidligere godkendte TM-segmenter. Motoren skal være konfigureret til at markere usikre oversættelser med lav confidence-score, så post-editor kan prioritere disse.

Fagspecifikke motorer gør en målbar forskel. En generisk NMT-motor opnår typisk BLEU 45 på medicinske tekster, mens en specialiseret motor når 58. Denne forbedring reducerer post-editing tid med 30%.
3. Human post-editing
Post-editoren gennemgår output systematisk efter ISO 18587 guidelines. Processen omfatter tre lag: Terminologisk validering (stemmer alle fagtermer med godkendt termbase?), kontekstuel korrektion (giver sætningerne mening i sammenhængen?) og stilistisk tilpasning (matcher tonen målgruppens forventninger?).
Professionelt tip: Brug farvemarkering til at skelne mellem kritiske rettelser (rød), terminologiske justeringer (gul) og stilistiske forbedringer (grøn). Dette letter senere analyse af fejlmønstre.
Human-in-loop oversættelse matcher eller overgår professionelle løsninger og foretrækkes konsekvent af evaluatorer i blindtests. Studier viser at erfarne post-editors identificerer 94% af kritiske fejl, mens automatisk QA kun fanger 67%.
4. QA/LQA (Language Quality Assurance)
QA-fasen anvender både automatiske og manuelle checks. DQF-platforme scanner for: Udeladte segmenter, inkonsistent terminologi, formatfejl, tal-diskrepanser og broken tags. MQM-evaluering scorer output på dimensioner som nøjagtighed, flydende sprog, terminologi, stil og locale-konventioner.
Højrisiko-dokumenter gennemgår dual review, hvor en anden fagspecialist validerer post-editorens arbejde. Denne anden reviewer fokuserer på: Kritiske fejl der kan påvirke sikkerhed eller compliance, terminologisk konsistens på tværs af dokumentet og overholdelse af style guides.
5. Feedback og løbende forbedring
Alle korrektioner fra post-editing og QA feeds tilbage til AI-systemet. Nye termpars tilføjes termbases, korrigerede segmenter opdaterer TM, og fejlmønstre bruges til at finjustere motorens parametre. Denne feedback-loop er afgørende: PE er samlet set 66% hurtigere end traditionel oversættelse, og hastigheden forbedres yderligere over tid.
LQA-output dokumenterer kvalitetsforbedringer. Første batch af dokumenter kan have 12 fejl per 1000 ord, mens batch ti er nede på 3 fejl per 1000 ord. Denne progression beviser systemets læringskurve.
Metode | Hastighed | Nøjagtighed | Compliance | Omkostning |
Ren maskinoversættelse | 10.000 ord/time | 73% | Ikke-compliant | Meget lav |
AI+HUMAN workflow | 3.000 ord/time | 98% | Fuld compliance | Medium |
Traditionel oversættelse | 500 ord/time | 97% | Fuld compliance | Høj |
Human + light PE | 2.000 ord/time | 96% | Compliance med forbehold | Medium-høj |
For detaljeret implementering, se vores guide til workflow for compliant dokumentoversættelse. Specifik vejledning til kvalitetssikring findes i AI+human kvalitetssikring for compliance.
Når workflowet følges stringent, er næste skridt at sikre den løbende kvalitet gennem validering og optimering.
Validering og løbende optimering af dit workflow
Et AI+HUMAN workflow er ikke statisk. Kontinuerlig måling og justering sikrer, at kvaliteten forbliver høj, mens effektiviteten forbedres.
QA metrics leverer objektive kvalitetsindikatorer. DQF scorer output på en skala fra 0-100 baseret på fejlfrekvens og alvorlighed. Målsætningen for regulerede brancher er minimum 95. MQM kategoriserer fejl i: Kritiske (påvirker mening eller sikkerhed), større (påvirker forståelse) og mindre (stilistiske). BLEU-score måler maskinens råoutput, mens EMQ (Error Markup Quality) vurderer post-editorens arbejde.
Kritiske fejltyper der kræver systematisk sporing:
Omvendt mening: “Må ikke” bliver til “må”
Udeladt information: Advarsler eller kontraindikationer mangler
Forkert enhed: mg bliver til g (1000x fejl i dosering)
Terminologisk inkonsistens: Samme koncept oversættes forskelligt
Kulturel misforståelse: Datoer, adresser, telefonnumre formateret forkert
Audit trail og sporbarhed er lovkrav under EU AI Act. Systemet skal logge: Tidspunkt for hver proces-fase, identitet på AI-motor og version, navn på post-editor og reviewer, alle terminologiske beslutninger og begrundelser for afvigelser fra standard-workflow. Denne dokumentation skal opbevares i minimum 10 år for medicinske devices og 7 år for finansielle dokumenter.
Feedback-loops og monitorering sikrer kontinuerlig forbedring. Månedlige reviews analyserer: Gennemsnitlig fejlrate per dokumenttype, mest almindelige fejlkategorier, post-editing tid per sprogpar og kunde-feedback på leverancer. Human-in-the-loop og LQA/MQM instrumenter forbedrer AI’ens output over tid, samtidig med at compliance sikres.
Eksempel på fejlrettelse og læring: AI oversætter konsekvent “device” som “apparat” i stedet for kundens foretrukne “medicinsk udstyr”. Post-editor retter fejlen og tilføjer reglen til termbases. Næste gang AI møder “device” i medicinsk kontekst, anvender den automatisk “medicinsk udstyr”. Over 50 dokumenter reduceres denne fejltype fra 23 forekomster til 0.
“Systematisk feedback fra post-editors forbedrede vores AI-motors terminologiske præcision med 41% over seks måneder, hvilket reducerede gennemsnitlig post-editing tid fra 2,3 timer til 1,4 timer per 1000 ord.”
Brugerdata og reviewcykler opdaterer AI-systemet sikkert. I modsætning til public cloud NMT-systemer, hvor dine data potentielt træner konkurrenters modeller, sikrer et proprietært system at jeres domæneviden forbliver jeres. Hver korrektion styrker systemets performance specifikt for jeres terminologi og stil.
For virksomheder der håndterer store mængder regulatorisk dokumentation, anbefaler vi at implementere et effektivt workflow regulatoriske dokumenter, der integrerer disse validerings- og optimeringsmekanismer fra start.
Med validering og optimering på plads kan du dokumentere for regulatorer og ledelse, at dit workflow giver resultater.
Få eksperthjælp til AI+human kvalitetssikring
At implementere et compliant AI+HUMAN workflow kræver både teknologisk infrastruktur og domæneekspertise. AD VERBUM kombinerer 25 års erfaring i regulerede brancher med proprietær LLM-teknologi hostet på EU-servere.
Vores workflow sikrer compliance gennem ISO 18587-certificerede post-editors med fagspecifik baggrund, proprietær AI trænet på jeres terminologi og style guides, og fuld audit trail dokumentation der opfylder EU AI Act, FDA og EMA krav. Vi leverer 3-5x hurtigere end traditionelle workflows uden at kompromittere kvalitet. Vores netværk af 3.500+ fagspecialister dækker livsvidenskab, jura, finans og produktion.
Hver virksomhed har unikke krav til terminologi, tone og compliance. Vi designer skræddersyede workflows der integrerer med jeres eksisterende systemer og processer. Uanset om du skal oversætte kliniske prøveprotokoller, patentansøgninger eller finansielle rapporter, sikrer vores AI+HUMAN tilgang både hastighed og præcision.
Udforsk vores AI+human oversættelsestjenester for at se, hvordan vi håndterer komplekse projekter. Vores AI-baserede workflow-løsninger kombinerer LLM-teknologi med menneskelig ekspertise. For life sciences-virksomheder tilbyder vi specialiseret oversættelse til life sciences med fuld MDR og GxP compliance.
Når du er klar til sikker og effektiv AI+human workflow, kan vores eksperter hjælpe hele vejen.
Ofte stillede spørgsmål
Hvilke regulatoriske krav skal overholdes ved AI+human oversættelser?
Du skal følge EU AI Act, FDA og EMA krav samt ISO 18587 for post-editing og audit trail dokumentation. Høj-risiko anvendelser kræver fuld menneskelig validering og sporbarhed.
Hvilke værktøjer bruges til at måle kvaliteten af et workflow?
DQF, MQM og BLEU-score er standarder for procesovervågning, audit og løbende optimering. DQF giver +41% redigeringseffektivitet gennem objektiv fejlmåling og systematisk feedback.
Kan AI alene bruges til garanti for compliance i oversættelse?
Nej, menneskelig efterredigering er obligatorisk for compliance og terminologisk nøjagtighed i kritiske domæner. AI fejler konsekvent på kontekst, nuancer og domænespecifik terminologi.
Er workflowet det samme for alle sprogpar?
Nej, workflowet varierer især for lavressourcesprog og sprogretning. PE er hurtigere L2→L1, mens menneskelig styring er afgørende for L1→L2, hvor AI-performance typisk er lavere.
Hvor lang tid tager det at implementere et AI+human workflow?
Implementering tager typisk 4-8 uger afhængig af kompleksitet. Dette inkluderer AI-konfiguration, termbase-opbygning, post-editor træning og pilottest på repræsentative dokumenter før fuld udrulning.
Anbefaling


