
LLM i regulerede brancher: Compliance og præcision
- for 4 dage siden
- 8 min læsning

Large Language Models (LLM) er defineret som avancerede sprogmodeller, der forstår kontekst og instruktioner på et niveau, der gør dem anvendelige i regulerede brancher som life sciences, jura og finans. Rollen af LLM i regulerede brancher er ikke blot at accelerere oversættelsesprocesser, men at sikre, at hvert eneste ord overholder gældende lovgivning, terminologikrav og databeskyttelsesregler. EU AI Act, GDPR og ISO-standarder som ISO 17100 og ISO 18587 sætter præcise rammer for, hvordan LLM må anvendes. Denne artikel forklarer, hvad det kræver at implementere LLM ansvarligt, og hvorfor AI+HUMAN hybrid translation er det eneste forsvarlige valg i højrisikosektorer.
Hvordan LLM understøtter compliance i regulerede brancher
LLM understøtter compliance ved at kombinere kontekstforståelse med styrbar terminologihåndhævelse, hvilket traditionel maskinoversættelse (MT) og neural maskinoversættelse (NMT) ikke kan matche. Hvor et NMT-værktøj som DeepL oversætter sætning for sætning uden at kende dokumentets juridiske eller medicinske kontekst, kan en LLM instrueres til at anvende kundens godkendte ordliste konsekvent på tværs af tusindvis af sider. Det er præcis denne egenskab, der gør LLM til et fundament i professionel oversættelse til virksomheder i regulerede sektorer.

EU AI Act stiller krav om risikostyring, teknisk dokumentation, transparens og menneskelig overvågning for højrisiko-AI-systemer, og disse krav træder fuldt i kraft den 2. august 2026. Det betyder, at virksomheder, der anvender LLM i kliniske, juridiske eller finansielle oversættelsesprocesser, allerede nu skal have dokumenterede compliance-procedurer på plads. Manglende overholdelse er ikke blot en bøderisiko. Det er en direkte trussel mod virksomhedens licens til at operere.
Konkret stiller EU AI Act følgende krav til LLM-anvendelse i regulerede kontekster:
Risikostyring: Dokumenterede risikovurderinger for hvert AI-system, der anvendes i højrisikokontekster, herunder oversættelse af medicinsk udstyrsdokumentation og juridiske kontrakter.
Data governance: Kontrol over de data, der bruges til at træne og instruere modellen, med krav om anonymisering og pseudonymisering i overensstemmelse med GDPR.
Human oversight: Dokumenteret kompetence og myndighed til at intervenere i AI-systemets output, jf. EU AI Act Art. 14.
Transparens: Brugere skal informeres om AI-interaktion, og AI-genereret indhold skal markeres synligt, uanset risikoklassifikation, jf. Article 50.
Audit trails: Logning af AI-systemets beslutninger og outputs, så der altid kan dokumenteres et revisionsspor.
Professionelt tip: Kortlæg alle dokumenttyper, der oversættes i din organisation, og klassificer dem efter EU AI Acts risikoramme, inden du implementerer LLM. En medicinsk brugsanvisning er højrisiko. En intern kommunikationsmail er lavrisiko. Behandlingen skal afspejle denne forskel.
GDPR og EU AI Act overlapper på et centralt punkt: begge kræver, at behandling af personoplysninger sker med dokumenteret hjemmel, og at AI-systemer ikke eksponerer disse data for tredjeparter. Offentlige NMT-løsninger opfylder ikke dette krav, fordi data sendes til og behandles på eksterne servere. En proprietær LLM, der kører på lukkede EU-servere, er den eneste teknisk forsvarlige løsning for virksomheder med GDPR-forpligtelser.
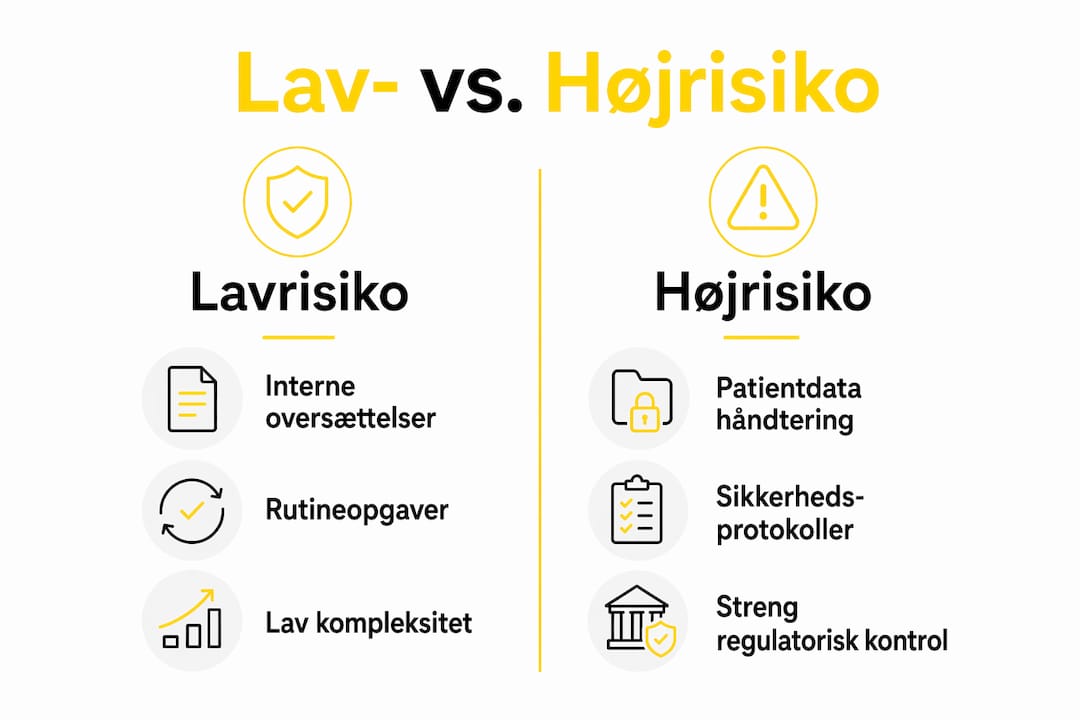
Lav- vs. højrisiko LLM-brug: Hvad er forskellen?
Ikke al LLM-anvendelse i regulerede sektorer bærer samme risikoniveau, og governance-kravene skal afspejle denne forskel. Forståelsen af denne distinktion er afgørende for at implementere LLM ansvarligt og effektivt.
Kategori | Lavrisiko-anvendelse | Højrisiko-anvendelse |
Eksempel | Oversættelse af interne retningslinjer, kodegenerering til testmiljøer | Oversættelse af kliniske forsøgsresultater (COA), patentansøgninger, medicinsk udstyrsdokumentation |
Human oversight | Stikprøvekontrol acceptabel | 100% menneskelig review obligatorisk |
Dokumentationskrav | Begrænset logning | Fuld audit trail og godkendelsesdokumentation |
Terminologikontrol | Anbefalet | Obligatorisk med godkendt termbase |
Regulatorisk ramme | Intern politik tilstrækkelig | EU AI Act, MDR, HIPAA, ISO 17100/18587 |
Konsekvens ved fejl | Intern korrektion | Regulatorisk sanktion, produkttilbagekaldelse, patientskade |
Inden for industriel robotik anbefales en lagdelt LLM-implementering, hvor man starter i lavrisikolag som kodegenerering, inden man bevæger sig mod avancerede driftssystemer. Det samme princip gælder for oversættelse: begynd med interne dokumenter, valider modellens terminologioverholdelse, og udvid derefter til regulerede dokumenttyper med fuld human oversight på plads.
Operational thresholds og dokumenterbar menneskelig godkendelse er afgørende for at balancere automatisering og ansvar. Det betyder i praksis, at organisationen skal definere præcist, hvilke dokumenttyper og risikoniveauer der kræver menneskelig godkendelse, inden output frigives. Ikke alle AI-handlinger kræver menneskelig involvering, men alle højrisikosituationer skal have en dokumenteret menneskelig beslutning bag sig. Denne skelnen er ikke blot god praksis. Den er et lovkrav.
Datakvalitet og governance: Fundamentet for compliant LLM-oversættelse
Data governance er ikke et sideprojekt i LLM-implementeringer. Det er en forudsætning for, at AI-oversættelse overhovedet kan levere pålidelige og compliant resultater. AI understreger eksisterende svagheder i data governance, og organisationer, der ikke har styr på deres terminologidatabaser og oversættelsesminder, vil opleve, at LLM forstærker disse svagheder frem for at kompensere for dem.
Konkret betyder god data governance i en LLM-oversættelseskontekst følgende:
Vedligehold en godkendt termbase (TB). Alle fagtermer, produktnavne og regulatoriske betegnelser skal være defineret og godkendt af fageksperter, inden de indlæses i LLM-systemet. En termbase, der ikke er opdateret siden 2022, er en compliance-risiko.
Integrer Translation Memories ™ systematisk. Tidligere godkendte oversættelser skal indlæses som reference, så LLM ikke genopfinder løsninger på allerede løste terminologiproblemer. Dette sikrer konsistens på tværs af dokumentversioner og markeder.
Anonymiser og pseudonymiser personoplysninger. Inden et dokument med patientdata eller personidentificerbare oplysninger sendes til LLM-behandling, skal disse data maskeres. Mandatory human review for outputs affecting data subjects’ rights er en GDPR-grundforpligtelse, ikke en valgmulighed.
Etabler logging og audit trails. Hvert oversættelsesjob skal logges med tidsstempel, anvendt model, reviewer-identitet og godkendelsesstatus. Dette er dokumentationsgrundlaget ved regulatoriske inspektioner.
Gennemfør periodiske governance-reviews. Termbasen, TM og LLM-instruktionerne skal revideres kvartalsvist eller ved større regulatoriske ændringer, f.eks. opdateringer til MDR eller nye EDPB-retningslinjer.
Professionelt tip: Behandl din termbase som et levende regulatorisk dokument, ikke som en statisk liste. Udpeg en terminologiansvarlig med faglig baggrund i den relevante sektor, og kræv godkendelse fra denne person, inden nye termer indlæses i LLM-systemet.
Dårlig data governance manifesterer sig typisk som inkonsistent terminologi på tværs af dokumenter, oversættelsesfejl ved produktnavne og regulatoriske betegnelser, samt manglende sporbarhed ved compliance-audits. I regulerede brancher som life sciences og finans kan disse fejl have direkte konsekvenser for produktgodkendelser og myndighedstilladelser. AI kan ikke erstatte menneskelig kontrol i komplekse og regulerede miljøer uden styrket governance og ansvarlighed. Det er ikke en begrænsning ved LLM-teknologien. Det er en arkitektonisk realitet, som ansvarlige implementeringer skal bygges omkring.
Praktiske anvendelser: LLM i AI+HUMAN oversættelse for regulerede industrier
LLM’s praktiske fordele i regulerede brancher realiseres fuldt ud, når teknologien kombineres med menneskelig fagekspertise i et struktureret workflow. Professionel AI-oversættelse med efterredigering (MTPE) er ikke en ny idé, men LLM-baserede systemer hæver kvalitetsloftet markant sammenlignet med ældre NMT-løsninger, fordi modellen forstår instruktioner og kontekst frem for blot at oversætte sætning for sætning.
Konkrete anvendelsesområder, hvor LLM skaber dokumenterbar værdi i regulerede sektorer:
Kliniske forsøgsdokumenter (COA/CRF): LLM instrueres til at anvende ICH-terminologi og kundens godkendte ordliste. En fagekspert med medicinsk baggrund gennemgår output og verificerer, at ingen negationer er udeladt, og at dosisangivelser er korrekte. Fejl i disse dokumenter kan forsinke myndighedsgodkendelser med måneder.
Patentansøgninger: Juridisk præcision kræver, at termer som “claim”, “embodiment” og “prior art” oversættes konsekvent og korrekt. LLM med integreret juridisk termbase leverer dette, mens en patentjurist-lingvist validerer output.
Industrielle sikkerhedsmanualer: En forkert oversættelse af “må ikke aktiveres under tryk” til “aktiveres under tryk” er ikke en sproglig fejl. Det er en potentiel arbejdsulykke. LLM-systemer med terminologihåndhævelse reducerer denne risiko markant, men eliminerer den ikke uden menneskelig kontrol.
Finansielle prospekter og regulatoriske indberetninger: MiFID II og EMIR stiller krav til præcis terminologi i investordokumenter. LLM sikrer konsistens på tværs af hundredvis af sider, mens en finansekspert verificerer, at regulatoriske definitioner er korrekt gengivet.
Et AI-værktøj reducerede B2B-kundeinteraktionstid med 90 % i 53 markeder, men menneskelig kontrol forbliver afgørende i regulerede brancher. Effektivitetsgevinsten er reel og dokumenterbar, men den må aldrig opnås ved at fjerne det menneskelige sikkerhedsnet. AD VERBUM leverer præcis oversættelse til regulerede industrier ved at kombinere hastigheden ved AI-oversættelse med menneskelige fageksperters kvalitetssikring. Det er denne kombination, der adskiller professionel LLM-baseret oversættelse fra generiske NMT-løsninger.
Den afgørende forskel ved AD VERBUMs tilgang er, at LLM-modellen kører på lukkede EU-servere og aldrig eksponerer kundens data for offentlige cloud-miljøer. Virksomheder, der anvender DeepL eller Google Translate til oversættelse af patientjournaler eller uindgivne patenter, overtræder GDPR og NDA-forpligtelser. AD VERBUMs proprietære LLM-system er ISO 27001-certificeret og GDPR-compliant by design, ikke som et eftermonteret lag.
Vigtigste erkendelser
LLM i regulerede brancher kræver en kombination af proprietær teknologi, stærk data governance og dokumenteret menneskelig oversight for at opfylde EU AI Act, GDPR og sektorspecifikke standarder.
Punkt | Detaljer |
EU AI Act krav fra august 2026 | Dokumenteret risikostyring, human oversight og audit trails er lovpligtige for højrisiko-AI-systemer. |
Lav- vs. højrisiko governance | Højrisikodokumenter kræver 100% menneskelig review og obligatorisk terminologikontrol. |
Data governance som fundament | Opdaterede termbasen og Translation Memories er forudsætninger for compliant LLM-output. |
Proprietær LLM frem for NMT | Offentlige NMT-løsninger overholder ikke GDPR og kan ikke håndhæve terminologi konsekvent. |
AI+HUMAN hybrid translation | Kombinationen af LLM-hastighed og fagekspertens kontrol er den eneste forsvarlige model i regulerede sektorer. |
LLM og ansvar: Hvad mange implementeringer overser
Jeg har fulgt LLM-implementeringer i regulerede brancher tæt, og det mønster, jeg ser gentage sig, er dette: organisationer fokuserer på teknologien og glemmer governance-arkitekturen. De vælger en LLM-løsning, integrerer den i oversættelsesworkflowet, og opdager derefter, at de ikke har defineret, hvem der har myndighed til at godkende output, hvornår menneskelig review er obligatorisk, eller hvordan de dokumenterer compliance over for myndighederne.
Det er ikke et teknologiproblem. Det er et ledelsesproblem. EU AI Act Art. 14 kræver ikke blot, at der er et menneske i loopet. Det kræver, at dette menneske har dokumenteret kompetence og reel myndighed til at stoppe eller korrigere AI-systemet. En junior oversætter uden faglig baggrund i medicin eller jura opfylder ikke dette krav, uanset hvor god LLM-modellen er.
Den anden fejl, jeg ser, er behandlingen af data governance som en engangsopgave. Termbasen opdateres ved implementering og røres derefter ikke. Seks måneder senere er der kommet nye regulatoriske betegnelser, produktnavne er ændret, og LLM-systemet anvender forældet terminologi. I en sektor, hvor et enkelt forkert ord kan udløse en myndighedssanktion, er dette uacceptabelt.
Min anbefaling til beslutningstagere er klar: invester mindst lige så meget i governance-arkitekturen som i selve LLM-teknologien. Udpeg en compliance-ansvarlig for AI-oversættelse. Definer operational thresholds skriftligt. Revidér termbasen kvartalsvist. Og vælg en leverandør, der kan dokumentere ISO-certificeringer og GDPR-compliance, ikke blot love det i et salgsmøde. Proprietær LLM til regulerede brancher er ikke en luksus. Det er en compliance-nødvendighed.
— Viestarts
Sådan leverer AD VERBUM compliant AI-oversættelse
AD VERBUM kombinerer hastigheden ved AI-oversættelse med menneskelige fageksperters kvalitetssikring i et dokumenteret AI+HUMAN hybrid translation workflow. Med over 25 års erfaring, ISO 9001, ISO 17100, ISO 18587, ISO 13485 og ISO 27001-certificeringer samt et netværk af 3.500+ fagekspert-lingvister er AD VERBUM bygget til at håndtere de krav, regulerede brancher stiller. Alle data behandles på lukkede EU-servere, og ingen kundedata eksponeres for offentlige cloud-miljøer. Resultatet er professionel oversættelse til virksomheder i life sciences, jura, finans og industri, der er compliant by design. Læs mere om AD VERBUMs branchefokuserede løsninger og find den rette tilgang til din sektor.
FAQ
Hvad er rollen af LLM i regulerede brancher?
LLM er defineret som kontekstforstående sprogmodeller, der kan instrueres til at håndhæve godkendt terminologi og overholde regulatoriske krav i oversættelsesprocesser. I regulerede brancher som life sciences og jura erstatter LLM ikke menneskelig ekspertise, men forstærker præcision og konsistens markant.
Hvornår kræver EU AI Act menneskelig oversight ved LLM-brug?
EU AI Act Art. 14 kræver dokumenteret menneskelig overvågning med kompetence og myndighed til at intervenere for alle højrisiko-AI-systemer. Oversættelse af kliniske dokumenter, juridiske kontrakter og medicinsk udstyrsdokumentation falder typisk i højrisikokategorien.
Hvorfor er offentlige NMT-løsninger ikke compliant i regulerede sektorer?
Offentlige NMT-løsninger som DeepL og Google Translate sender data til eksterne servere, hvilket overtræder GDPR og NDA-forpligtelser ved behandling af patientdata eller fortrolige forretningsdokumenter. De kan heller ikke pålideligt håndhæve kundespecifik terminologi, hvilket skaber inkonsistens i regulatoriske dokumenter.
Hvad er best practices for data governance i LLM-oversættelse?
Best practices inkluderer vedligeholdelse af en godkendt og opdateret termbase, systematisk integration af Translation Memories, anonymisering af personoplysninger inden LLM-behandling samt etablering af logging og audit trails for hvert oversættelsesjob. Data governance er en forudsætning, ikke et tilvalg, for pålideligt LLM-output.
Hvad adskiller LLM-baseret oversættelse fra traditionel maskinoversættelse?
LLM forstår kontekst og kan følge specifikke instruktioner, f.eks. “oversæt altid ‘device’ som ‘apparat’ i henhold til kundens ordliste.” Traditionel MT og NMT oversætter sætning for sætning uden kontekstforståelse og kan ikke håndhæve terminologi konsekvent, hvilket gør dem uegnede til regulerede dokumenttyper.
Anbefaling