
Hvorfor NMT kan feile i regulerte bransjer 2026
- 8. mars
- 8 min lesing

Statistikken er slående: 38% av juridiske AI-oversettelser inneholder kritiske feil uten menneskelig validering. I regulerte industrier som farmasi, jus og teknologi kan slike feil føre til helserisiko, juridiske sanksjoner eller tekniske katastrofer. Neural Machine Translation (NMT) mangler grunnleggende mekanismer for presisjon og compliance, noe som gjør offentlige verktøy uegnede for sensitive dokumenter. Denne artikkelen forklarer hvorfor NMT svikter, hvilke tekniske begrensninger som forårsaker feil, og hvordan sikre AI+HUMAN arbeidsflyter beskytter deres virksomhet.
Innholdsfortegnelse
Hvordan og hvorfor NMT kan feile: tekniske og mekaniske forklaringer
Compliance og datasikkerhet: hvor NMT svikter i regulerte miljøer
Sammenligning: NMT vs. proprietær LLM-basert AI + menneskelig kontroll
Implementering av trygg oversettelsespraksis i høyrisikoindustrier
Slik sikrer du nøyaktige og compliant oversettelser med AD VERBUM
Nøkkelpunkter
Punkt | Detaljer |
NMT har tekniske begrensninger | Hallucinasjoner, manglende kontekstforståelse og terminologikontroll skaper kritiske feil i regulerte oversettelser. |
Datasikkerhet og compliance | Offentlig NMT sender sensitive data til usikre skyer og bryter GDPR, HIPAA og MDR krav. |
Proprietære AI+HUMAN løsninger | Privat LLM arkitektur med menneskelig ekspertise sikrer presisjon, trygghet og regulatorisk overholdelse. |
ISO standarder kreves | Høyrisikoindustrier må følge ISO 17100, ISO 18587 og ISO 27001 for kvalitetssikring og informasjonssikkerhet. |
Implementering reduserer risiko | Hybrid arbeidsflyt med terminologistyring og kontinuerlig QA sikrer compliant oversettelser. |
Betydningen av presis oversettelse i regulerte industrier
Industrier som farmasi, juridiske tjenester og medisinsk utstyrsproduksjon opererer under strenge regulatoriske rammer. En enkelt feiloversettelse i en pasientinformasjonsbrosjyre kan føre til helsefare. En misforstått klausul i en kontrakt kan koste millioner i erstatningskrav. En feilaktig sikkerhetsinstruksjon i industrielt utstyr kan føre til ulykker.
Disse sektorene krever absolutt nøyaktighet fordi konsekvensene av feil er umiddelbare og alvorlige. ISO standarder som ISO 17100 (oversettelseskvalitet) og ISO 18587 (post-editering av maskinoversettelse) setter minimumskrav for kvalitetssikring. Regulatoriske krav som GDPR (databeskyttelse), HIPAA (helseinformasjon) og MDR (medisinsk utstyr) legger juridiske forpliktelser på hvordan dokumenter må oversettes og håndteres.
Nødvendigheten av compliance og risiko ved feil i livsviktige sektorer kan ikke overvurderes. Feil i kliniske studier, patentsøknader eller sikkerhetsdatablader skaper både juridisk ansvar og omdømmetap. Nøyaktighet er ikke bare en kvalitetsmetrikk, men en grunnleggende forutsetning for virksomheten.
Viktige områder der presisjon er kritisk:
Pasientinformasjon og kliniske studieprotokoller
Juridiske kontrakter og patentdokumentasjon
Regulatoriske innleveringer til helsemyndigheter
Sikkerhetsdatablader og bruksanvisninger for medisinsk utstyr
Compliance dokumentasjon for internasjonale markeder
Hvordan og hvorfor NMT kan feile: Tekniske og mekaniske forklaringer
Neural Machine Translation opererer på statistiske sannsynligheter, ikke semantisk forståelse. Systemet analyserer millioner av setningspar og lærer mønstre, men forstår ikke betydning eller kontekst. Dette skaper tre kritiske svakheter.

Først, NMT kan hallusinere og produsere informasjon som ikke finnes i kildeteksten. I medisinske dokumenter kan systemet endre “non-toxic” til “toxic” ved å utelate negtasjonen, eller oppfinne doseringsanvisninger som ikke var i originalen. Disse feilene oppstår uten varsel eller usikkerhetsindikatorer.
Andre, NMT mangler domenekunnskap. Tekniske termer som “suit” kan bety “dress” (klær) eller “lawsuit” (søksmål) avhengig av kontekst. Uten faglig forståelse velger systemet basert på statistisk sannsynlighet, ikke faktisk betydning. I juridiske dokumenter kan dette snu hele argumenter.
Tredje, 38% av juridiske AI-oversettelser inneholder kritiske feil uten menneskelig ekspertise ai oversettelse som validerer output. Systemet kan ikke selvregulere eller identifisere egne feil.
Type feil | Eksempel kilde | NMT output | Konsekvens |
Hallusinasjon | “Administer 5mg daily” | “Administer 15mg daily” | Potensielt dødelig overdosering |
Kontekstfeil | “File the suit by Monday” | “Lever dressen innen mandag” | Tapt søksmålsfrist |
Terminologibrudd | “Device” (godkjent term: “Apparatus”) | “Enhet” | Regulatorisk avvisning |
Negasjonsfeil | “Do not expose to heat” | “Eksponér for varme” | Produktskade eller fare |
Mer detaljert analyse av NMT feil i regulerte bransjer viser at feil ofte oppstår i komplekse setningsstrukturer, negasjoner og fagspesifikk terminologi.
Vanlige tekniske fallgruver:
Manglende kontekstvindu som fører til inkonsistente termer
Ingen terminologidatabase integrasjon
Overconfidence i feil prediksjoner uten usikkerhetsscore
Manglende evne til å håndtere tvetydighet
Proffetips: Implementer alltid menneskelig gjennomgang av kritiske seksjoner før publisering, spesielt for negasjoner, doser og juridiske forpliktelser.
Compliance og datasikkerhet: Hvor NMT svikter i regulerte miljøer
Offentlige NMT verktøy som Google Translate eller DeepL sender teksten til eksterne servere for behandling. Når du limer inn upubliserte patentdata, pasientjournaler eller konfidensielle kontrakter, sendes denne informasjonen til leverandørens sky. Dette bryter fundamentalt med GDPR artikkel 32 (sikkerhetstiltak) og HIPAA Privacy Rule.
Over 60% av bedrifter undervurderer risikoen ved offentlig NMT og datalekkasjer. Data kan lagres, analyseres eller brukes til å trene fremtidige modeller. For regulerte industrier er dette uakseptabelt.
GDPR krever at personopplysninger behandles med passende sikkerhetstiltak og bare av databehandlere med tilstrekkelige garantier. HIPAA forbyr deling av beskyttet helseinformasjon (PHI) uten Business Associate Agreements (BAA). Offentlige NMT tjenester tilbyr sjelden eller aldri slike avtaler.
Brudd på GDPR og HIPAA kan føre til bøter på opptil 4% av global omsetning eller 20 millioner euro (GDPR), og opptil 1,5 millioner dollar per brudd (HIPAA). Viktigere er omdømmetapet og tapet av kundetillit.
“I regulerte sektorer er datasikkerhet ikke et teknisk spørsmål, men en juridisk og etisk forpliktelse. Hver oversettelse må behandles som konfidensiell inntil noe annet er godkjent.”
Konsekvenser av usikker NMT bruk:
Brudd på konfidensialitetsavtaler (NDA)
Eksponering av forretningshemmeligheter og intellektuell eiendom
Regulatoriske sanksjoner fra tilsynsmyndigheter
Tap av sertifiseringer som ISO 27001 (informasjonssikkerhet)
Erstatningskrav fra berørte pasienter eller klienter
Mer om oversettelseskvalitet i regulerte bransjer viser hvordan kvalitetssikring og datasikkerhet må integreres i hele oversettelsesarbeidsflyten. Ytterligere informasjon om risiko ved offentlig NMT understreker nødvendigheten av private, sertifiserte løsninger.
Sammenligning: NMT vs. proprietær LLM-basert AI + menneskelig kontroll
Forskjellen mellom offentlig NMT og AD VERBUM sin proprietære AI+HUMAN løsning ligger i arkitektur, kontroll og ansvarlighet.
Offentlig NMT er bygget for generell bruk på tvers av språk og domener. Den mangler mekanismer for å påtvinge terminologi, verifisere faktisk nøyaktighet eller sikre dataisolasjon. Systemet behandler medisinsk tekst på samme måte som turistguider.
Proprietære LLM-baserte systemer som AD VERBUM sin løsning er bygget med compliance som grunnlag. Large Language Models (LLM) kan instruereres eksplisitt: “Alltid oversett ‘Device’ som ‘Apparatus’ i henhold til kundens godkjente terminologidatabase.” NMT kan ikke motta eller følge slike instruksjoner pålitelig.
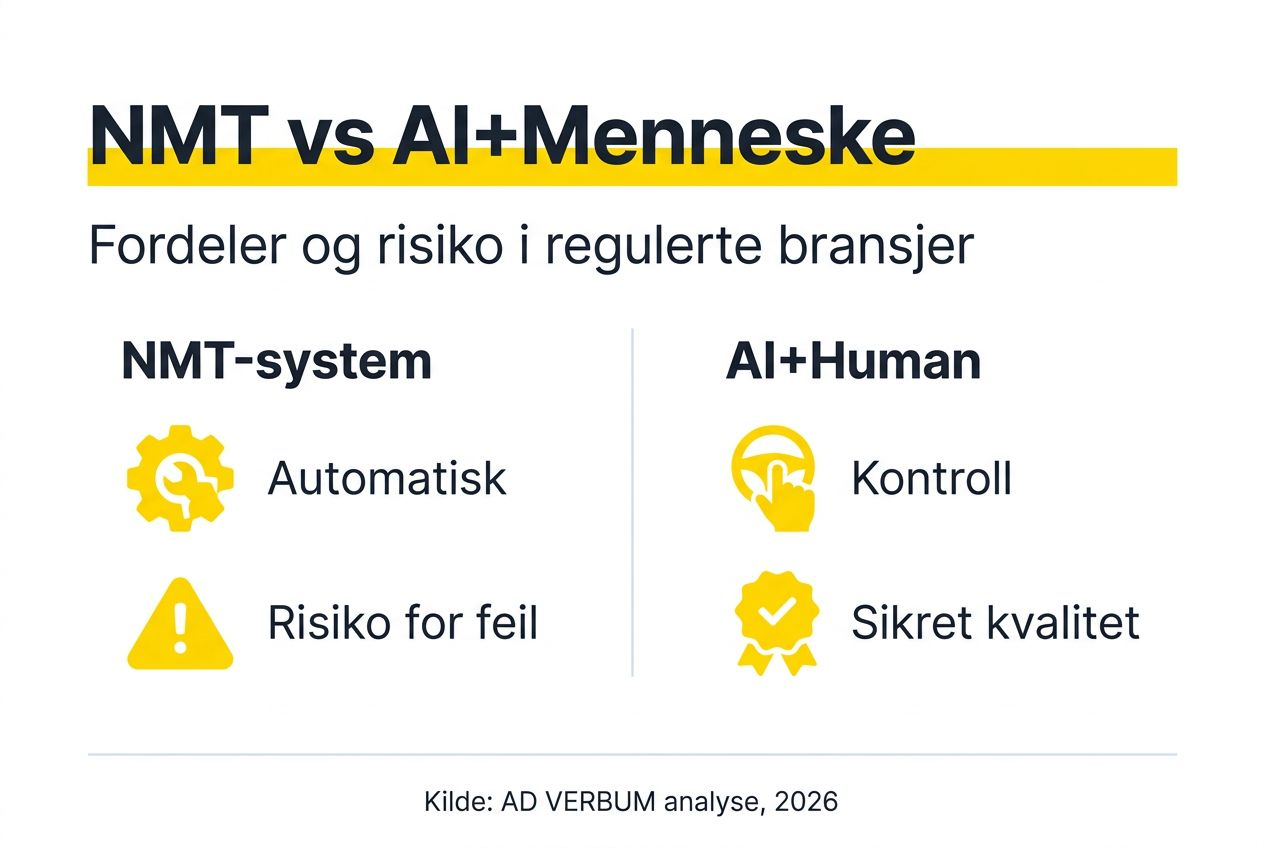
Egenskap | Offentlig NMT | AD VERBUM Proprietær AI+HUMAN |
Terminologikontroll | Ingen garantert konsistens | 100% terminologidatabase integrert |
Datasikkerhet | Offentlig sky, data deles | Privat EU sky, ISO 27001 sertifisert |
Kontekstforståelse | Begrenset til setningsnivå | Dokumentnivå med LLM-arkitektur |
Menneskelig validering | Ingen | Sertifiserte fageksperter (SME) |
Compliance | Ingen garantier | ISO 17100, ISO 18587, GDPR, HIPAA |
Ansvarlighet | Ingen | Fullt juridisk ansvar og kvalitetsgaranti |
Tilpasning | Generisk modell | Kundetilpasset med TM og TB |
Den menneskelige kvalitetssikring er kritisk for å oppnå nøyaktighet og compliance i AI-oversettelser. AI+HUMAN arbeidsflyten kombinerer LLM-effektivitet med menneskelig domenekunnskap.
Proprietære systemer integrerer Translation Memory ™ og Term Bases (TB) før AI-generering. Dette sikrer at godkjente oversettelser gjenbrukes konsistent. SME gjennomgang fanger opp kontekstfeil, kulturelle nyanser og regulatoriske krav som AI overser.
Viktige fordeler ved hybrid tilnærming:
Hastighet: 3 til 5 ganger raskere enn tradisjonell manuell oversettelse
Konsistens: Terminologi håndheves på tvers av tusenvis av sider
Sikkerhet: Data forlater aldri sertifisert infrastruktur
Compliance: Fullt sporbar kvalitetssikring for regulatoriske revisjoner
Les mer om menneskelig fagkompetanse i oversettelse og hvordan compliance prosess for oversettelse sikrer regulatorisk trygghet. Se også casestudie på menneskelig validering fra implementering i regulert industri.
Proffetips: Velg alltid leverandører som tilbyr både proprietær teknologi og sertifiserte fageksperter. Hybrid arbeidsflyt er ikke valgfritt i høyrisikoindustrier, det er en compliance-nødvendighet.
Implementering av trygg oversettelsespraksis i høyrisikoindustrier
Å etablere sikre oversettelsesarbeidsflyter krever systematisk planlegging og strengt fokus på compliance. Følg denne trinnvise prosessen.
Risikovurdering og klassifisering: Identifiser dokumenttyper etter sensitivitet og regulatoriske krav. Klassifiser innhold som krever ISO 17100 validering, HIPAA compliance eller MDR dokumentasjon.
Velg sertifisert leverandør: Verifiser at leverandøren har ISO 27001 (informasjonssikkerhet), ISO 9001 (kvalitetsledelse) og relevante bransjestandarder. Krev dokumentasjon på databehandlingsavtaler (DPA) og Business Associate Agreements.
Etabler terminologistyring: Bygg og vedlikehold godkjente Term Bases (TB) med fageksperter. Integrer TB direkte i oversettelsesplattformen for automatisk konsistenshåndhevelse.
Implementer AI+HUMAN arbeidsflyt: Kombiner proprietær LLM-teknologi med menneskelig SME-validering. Alle AI-genererte oversettelser må gjennomgås av sertifiserte fagfolk med domenekunnskap.
Kvalitetssikring og revisjon: Etabler totrinnsgodkjenning der første revisor fokuserer på teknisk nøyaktighet, andre på regulatorisk compliance. Dokumenter alle endringer for sporbarhet.
Kontinuerlig forbedring: Oppdater Translation Memory ™ og Term Bases regelmessig. Gjennomfør kvartalsvise gjennomganger av oversettelseskvalitet og compliance-metrikker.
Vanlige fallgruver å unngå:
Bruk av offentlige verktøy for sensitive dokumenter
Manglende terminologikontroll på tvers av prosjekter
Utelatelse av menneskelig validering for å spare tid
Ingen dokumentasjon av oversettelsesprosess for regulatoriske revisjoner
Manglende opplæring av interne team i compliance-krav
Implementering krever også intern opplæring. Alle som håndterer oversettelser må forstå GDPR, HIPAA og bransjespesifikke krav. Etabler klare retningslinjer for hva som kan oversettes hvor, og hvordan sensitive data skal håndteres.
Utforsk hvordan implementering av ai+menneske arbeidsflyt fungerer i praksis, og lær hvordan sikre terminologi i oversettelser med strukturerte TB-prosesser. Se også beste hybride oversettelsesleverandører 2026 for sammenligning av toppløsninger.
Oppsummering og neste steg for oversettelsesansvarlige
Offentlig NMT mangler fundamentale mekanismer for sikker og compliant oversettelse i regulerte bransjer. Tekniske begrensninger som hallucinasjoner, manglende terminologikontroll og kontekstforståelse skaper kritiske feil. Datasikkerhetsproblemer med offentlige skyer bryter GDPR, HIPAA og konfidensialitetsavtaler.
Proprietære AI+HUMAN løsninger løser disse utfordringene gjennom privat LLM-arkitektur, streng terminologihåndhevelse og sertifisert menneskelig ekspertvalidering. ISO-sertifiserte arbeidsflyter sikrer sporbarhet og compliance med regulatoriske krav.
Anbefalte handlingspunkter:
Gjennomfør umiddelbar risikovurdering av nåværende oversettelsespraksis
Eliminer bruk av offentlige NMT verktøy for sensitive dokumenter
Etabler partnerskap med ISO-sertifiserte leverandører som tilbyr AI+HUMAN løsninger
Bygg robuste Term Bases og Translation Memories med fageksperter
Implementer totrinnsgodkjenning med teknisk og compliance-fokusert validering
Dokumenter alle oversettelsesprosesser for regulatoriske revisjoner
Regelmessig evaluering av oversettelseskvalitet og compliance-status er essensielt. Teknologi og regelverk utvikler seg kontinuerlig. Hold deg oppdatert på nye ISO-standarder og regulatoriske endringer i deres bransje.
Slik sikrer du nøyaktige og compliant oversettelser med AD VERBUM
AD VERBUM tilbyr proprietære AI+HUMAN oversettelsesløsninger spesielt utviklet for høyrisikoindustrier. Med over 25 års erfaring og et nettverk på 3 500+ fageksperter kombinerer vi LLM-teknologi med menneskelig domenekunnskap.
Vår private EU-baserte infrastruktur er ISO 27001 sertifisert og fullt compliant med GDPR, HIPAA og MDR. Vi integrerer deres godkjente Translation Memories og Term Bases direkte i arbeidsflyten, sikrer terminologikonsistens og verifiserer teknisk nøyaktighet gjennom sertifiserte SME.
Utforsk våre professional translation løsninger for regulerte bransjer, eller lær mer om vår ai translation teknologi. Se hvordan vår arbeidsflyt for ai+human oversettelse sikrer både hastighet og compliance i deres oversettelsesprosjekter.
Vanlige spørsmål
Hva er de vanligste feilene NMT gjør i regulerte bransjer?
NMT gjør ofte hallucinasjoner der systemet oppfinner informasjon som ikke finnes i kildeteksten, spesielt i doseringsanvisninger og tekniske spesifikasjoner. Terminologifeil oppstår når domenespesifikke termer oversettes inkonsistent eller feil. Kontekstfeil skjer når flertydige ord oversettes basert på statistisk sannsynlighet i stedet for faktisk betydning i dokumentet.
Hvordan kan man redusere risikoen ved NMT i sensitive oversettelser?
Bruk proprietære AI-systemer med integrert terminologikontroll og streng domenehåndhevelse i stedet for offentlige verktøy. Kombiner alltid AI-output med menneskelig validering fra sertifiserte fageksperter som har domenekunnskap. Sikre at all databehandling skjer på ISO 27001 sertifisert infrastruktur uten eksponering til offentlige skyer. Les mer om å implementere ai+menneske arbeidsflyt i praksis.
Hvorfor er datasikkerhet spesielt viktig i bruk av NMT?
Oversettelser i regulerte bransjer inneholder ofte personopplysninger, helseinformasjon eller forretningshemmeligheter som er strengt beskyttet av GDPR og HIPAA. Offentlige NMT-tjenester sender data til eksterne servere hvor informasjonen kan lagres, analyseres eller brukes til modelltrening. Dette bryter konfidensialitetsavtaler og regulatoriske krav, og kan føre til store bøter og omdømmetap.
Hva skiller proprietære AI+human systemer fra offentlig NMT?
Proprietære systemer som AD VERBUM bruker private LLM-modeller som kan instruereres eksplisitt til å følge kundeens godkjente terminologi og stilguider. Menneskelige fageksperter validerer all output for teknisk nøyaktighet og regulatorisk compliance. Data behandles kun på ISO 27001 sertifisert infrastruktur uten noen eksponering til offentlige skyer, noe som sikrer full sporbarhet og juridisk ansvarlighet.
Anbefaling


