
Hva er proprietær AI? Guide for regulerte virksomheter
- 9. juni
- 7 min lesing

Proprietær AI er en AI-løsning der utvikleren beholder full kontroll over kildekode, modellparametere og treningsdata, og brukeren får kun tilgang til funksjonaliteten via kontrollerte grensesnitt. Denne modellen skiller seg fundamentalt fra åpen kildekode AI ved at ingen utenforstående kan inspisere, kopiere eller modifisere teknologien. Store aktører som OpenAI og Anthropic leverer proprietære modeller via API-tilgang uten å eksponere den underliggende arkitekturen. For virksomheter i regulerte bransjer som finans, helse og offentlig forvaltning betyr dette at proprietær AI kan tilby sterkere styring over data og drift, forutsatt at leverandøren opererer innenfor de rette juridiske og tekniske rammene.
Hva er proprietær AI, og hvordan skiller den seg fra åpen AI?
Proprietær AI, også kalt lukket kildekode AI eller “closed source AI”, er definert ved at kildekode og modellparametere holdes skjult for brukeren. Brukeren får stabile funksjoner levert som en tjeneste, men kan ikke verifisere modellens interne oppbygning. Dette er et bevisst valg fra utviklerens side, motivert av kommersielle interesser, sikkerhet og kvalitetskontroll.
Åpen kildekode AI, som modeller fra Meta (LLaMA) eller Mistral AI, gjør kode og parametere offentlig tilgjengelig. Dette gir teknisk innsikt og fleksibilitet, men krever at virksomheten selv tar ansvar for sikkerhet, drift og oppdateringer. For regulerte virksomheter uten dedikerte AI-team er dette sjelden en realistisk løsning.

Kommersielt utviklede proprietære modeller som GPT-4 fra OpenAI og Claude fra Anthropic integreres via API uten behov for egen infrastruktur. Dette senker terskelen for implementering betydelig. Utfordringen er at standard API-tilgang til disse tjenestene ikke automatisk oppfyller kravene til datasuverenitet og GDPR som regulerte bransjer er underlagt.
Proffetips: Ikke forveksle tilgang til en proprietær AI via API med privat AI. Privat AI krever i tillegg at data ikke brukes til treningsformål og at driften skjer i et isolert miljø.
Hvordan fungerer proprietær AI i regulerte miljøer?
Proprietær AI i regulerte sammenhenger krever mer enn bare en lisensavtale. Data må ikke brukes til treningsformål, og driften må skje i isolert cloud eller lokalt. Dette er ikke valgfritt i regulerte bransjer. Det er et juridisk krav.
De tekniske og kontraktsmessige elementene som kvalifiserer en proprietær AI-løsning som “privat AI” inkluderer:
Lukket kildekode og kontrollerte API-tilganger: Ingen ekstern part kan inspisere modellen eller dataene som behandles.
Isolert drift: Løsningen kjøres i en dedikert cloud-instans eller lokalt, adskilt fra leverandørens øvrige infrastruktur.
Databehandleravtale (DPA): GDPR krever klare instrukser og databehandleravtaler i henhold til Artikkel 28 når en tredjepart behandler persondata på vegne av virksomheten.
Vurdering av personvernkonsekvenser (DPIA): Ved høy risiko for registrerte personer er DPIA påkrevd før implementering.
Logging og revisjonsspor: All databehandling skal kunne dokumenteres og etterprøves.
Kryptering: Data i transitt og i hvile skal krypteres etter gjeldende standarder.
Databehandleren må forplikte seg til ikke å gjenbruke eller analysere virksomhetens data til egne formål. Dette må fremgå eksplisitt av kontrakten, ikke bare av generelle servicevilkår. Mange virksomheter oppdager for sent at standard vilkår hos store leverandører ikke oppfyller disse kravene.
Proffetips: Bruk denne enkle testen før du signerer: Kan leverandøren eller en tredjepart se, logge eller gjenbruke dataene som behandles av AI-systemet? Hvis svaret er ja, er det ikke privat AI.
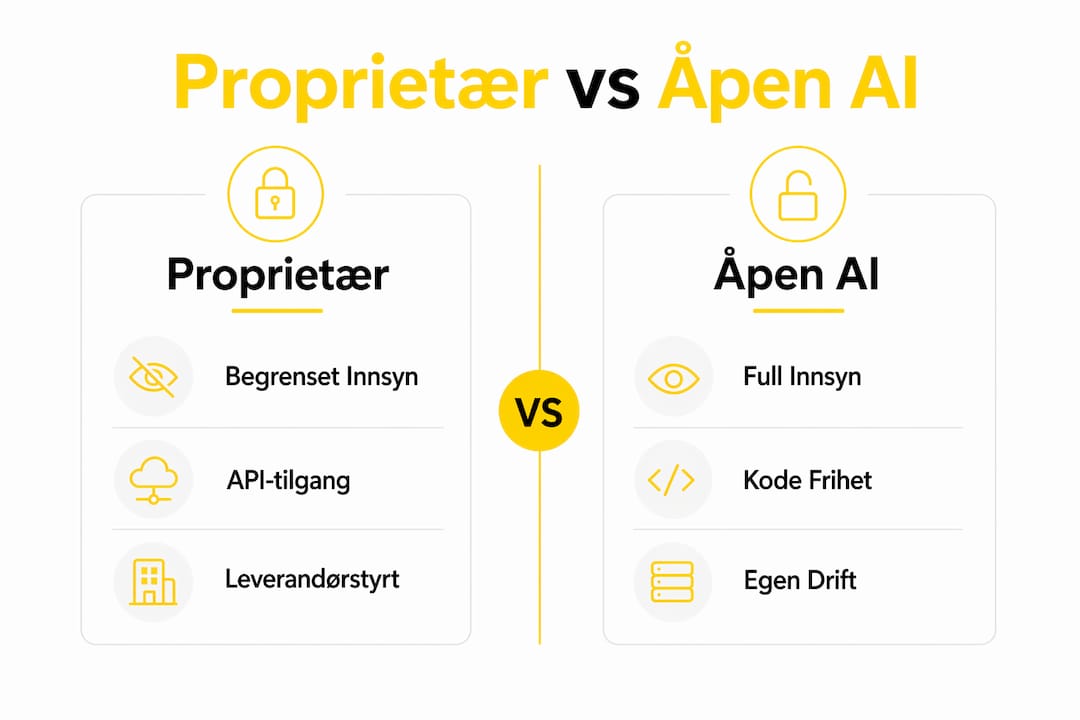
Fordeler og begrensninger: proprietær vs. åpen kildekode AI
Valget mellom proprietær og åpen kildekode AI er ikke et spørsmål om teknologi alene. Det er et strategisk og juridisk valg. Privat AI gir virksomheter styring over data, drift, tilgang og økonomi, og gjør compliance enklere å dokumentere.
Kriterium | Proprietær AI | Åpen kildekode AI |
Innsyn i modellen | Begrenset, kun via API | Full tilgang til kode og parametere |
Datasikkerhet | Høy ved korrekt kontrakt og isolasjon | Avhenger av egne sikkerhetstiltak |
Compliance-egnethet | God, forutsatt DPA og isolert drift | Krever betydelig egenkompetanse |
Vedlikehold og oppdateringer | Leverandørens ansvar | Virksomhetens eget ansvar |
Integrasjon og brukervennlighet | Ferdig tjeneste, rask implementering | Fleksibel, men ressurskrevende |
Kostnadskontroll | Forutsigbar, abonnementsbasert | Variabel, avhenger av infrastruktur |
Proprietær AI gir klare fordeler for virksomheter som ikke har kapasitet til å drifte egne modeller. Proprietær AI samler AI-bruk i ett kontrollert system med styring over modeller, data og bruk, i motsetning til fragmenterte løsninger basert på offentlige plattformer som ChatGPT.
Begrensningene er reelle. Virksomheten er avhengig av leverandørens veikart og kan ikke tilpasse modellen fritt. Manglende innsyn i modellens beslutningsprosesser kan være problematisk i bransjer der forklarbarhet er et regulatorisk krav, for eksempel i finansiell risikovurdering under EU AI Act.
Hvordan implementere proprietær AI trygt i regulerte virksomheter?
Trygg implementering av proprietær AI i regulerte bransjer krever en strukturert tilnærming. Ekstern konsulentbistand kan være avgjørende for å sikre at tekniske og juridiske krav møtes korrekt fra starten.
Følg disse trinnene i prioritert rekkefølge:
Kartlegg dataflyt og risikonivå. Identifiser hvilke data som vil behandles av AI-systemet. Klassifiser etter sensitivitet og regulatorisk kategori, for eksempel persondata, pasientdata eller forretningshemmeligheter.
Evaluer leverandører grundig. Krev dokumentasjon på ISO 27001-sertifisering, dataopphold i EU, og eksplisitte garantier om at data ikke brukes til trening. Sjekk om leverandøren tilbyr dedikert infrastruktur eller delt cloud.
Inngå databehandleravtale. Sørg for at DPA-en dekker Artikkel 28 i GDPR, inkludert instrukser om behandlingsformål, sletting og underleverandører.
Gjennomfør DPIA der det er påkrevd. For behandling av sensitive personopplysninger eller høyrisikooperasjoner er dette et lovkrav, ikke en anbefaling.
Etabler AI-governance rammeverk. Definer hvem som har ansvar for AI-systemet, hvordan det overvåkes, og hvilke prosedyrer som gjelder ved avvik eller sikkerhetsbrudd.
Implementer logging og revisjonsspor. All AI-assistert behandling skal kunne dokumenteres for intern revisjon og tilsynsmyndigheter.
Planlegg for løpende evaluering. AI-systemer endrer seg. Sett opp halvårlige gjennomganger av leverandørens vilkår, modellversjoner og compliance-status.
En moden AI-strategi inkluderer AI som et integrert lag i bedriftens infrastruktur, med fokus på governance, sikkerhet og datasuverenitet. Virksomheter som behandler AI som et isolert verktøy fremfor en strategisk infrastrukturkomponent, vil møte voksende compliance-utfordringer etter hvert som regulatoriske krav skjerpes.
Proffetips: Etabler et internt AI-register som dokumenterer alle AI-systemer i bruk, behandlingsformål, datatyper og ansvarlig eier. Dette er god praksis og vil sannsynligvis bli et formelt krav under EU AI Act.
Eksempler på proprietær AI i regulerte bransjer
Proprietær AI anvendes i dag i en rekke høyregulerte sektorer, og de konkrete brukstilfellene illustrerer hvorfor kontroll og sikkerhet er ikke-forhandlingsbare krav.
Finanssektoren bruker proprietære AI-modeller til kredittscoring, svindeldeteksjon og automatisert rapportering. Banker og forsikringsselskaper opererer under MiFID II, DORA og nasjonale finanstilsyn, og kan ikke eksponere kundedata mot offentlige AI-plattformer. En proprietær løsning med isolert drift og fullstendig revisjonsspor er her eneste reelle alternativ.
Helsesektoren anvender proprietær AI til journalanalyse, klinisk beslutningsstøtte og oversettelse av medisinsk dokumentasjon. Under HIPAA og MDR (Medical Device Regulation) er kravene til dataisolasjon og sporbarhet absolutte. Feil i medisinsk oversettelse eller databehandling er ikke et kvalitetsproblem. Det er en pasientrisiko.
Offentlig forvaltning bruker proprietær AI til dokumentbehandling, saksbehandlingsstøtte og flerspråklig kommunikasjon. Her er kravene til transparens, forklarbarhet og datasuverenitet særlig strenge, og løsninger som behandler data utenfor nasjonal eller EU-jurisdiksjon er i praksis utelukket.
AD VERBUM opererer i dette skjæringspunktet mellom teknologi og compliance. Med et proprietært LLM-basert AI-system driftet utelukkende på EU-servere, og et nettverk av over 3 500 fagspesialiserte lingvister, leverer AD VERBUM AI+HUMAN hybrid translation for kliniske dokumenter, patentsøknader og juridiske kontrakter. Terminologikontroll er ikke en funksjon. Det er en garanti. Modellen er instruksjonsbasert og følger kundens godkjente terminologibaser og stilguider, noe verken Google Translate eller DeepL kan gjøre pålitelig.
Viktigste erkjennelser
Proprietær AI er det eneste realistiske valget for regulerte virksomheter som krever datasuverenitet, compliance og kontroll over AI-bruk i ett integrert system.
Punkt | Detaljer |
Definisjon og kontroll | Proprietær AI holder kildekode og data lukket; brukeren får tilgang via kontrollerte grensesnitt. |
Juridiske krav | GDPR Artikkel 28 krever databehandleravtale og eksplisitte instrukser ved bruk av tredjeparts AI. |
Fordel fremfor åpen AI | Proprietær AI gir forutsigbar drift, kostnadskontroll og enklere compliance enn åpen kildekode. |
Implementeringsprioritet | Start med dataflyt-kartlegging og leverandørevaluering før teknisk integrasjon. |
Strategisk perspektiv | AI-governance og datasuverenitet bør behandles som infrastruktur, ikke som et verktøyvalg. |
Proprietær AI er et strategisk valg, ikke bare et teknologivalg
Jeg har sett mange virksomheter gjøre den samme feilen: de velger en offentlig AI-plattform fordi den er rask å komme i gang med, og oppdager ett år senere at de har bygget kritiske prosesser på et fundament som ikke tåler et tilsyn. Tidlig valg av privat AI er ikke bare god praksis. Det er en kostnadsbesparing. Å rydde opp i ettertid, reforhandle kontrakter, migrere data og dokumentere behandlingsgrunnlag er langt dyrere enn å gjøre det riktig fra starten.
Det som overrasker meg er at mange beslutningstakere fortsatt behandler AI-valget som et IT-spørsmål delegert til teknisk avdeling. Proprietær AI i regulerte bransjer er et juridisk, strategisk og operasjonelt spørsmål som krever involvering fra ledelse, juridisk avdeling og compliance-funksjonen. Teknologien er sjelden problemet. Styringsstrukturen rundt den er det.
Min klare anbefaling til ledere i finans, helse og industri: still leverandøren tre spørsmål før du signerer. Kan de garantere at data ikke forlater EU? Kan de dokumentere at data ikke brukes til trening? Og kan de levere et fullstendig revisjonsspor? Hvis ett av svarene er nei eller uklart, er løsningen ikke klar for regulert bruk.
— Viestarts
Slik hjelper AD VERBUM regulerte virksomheter med AI-basert oversettelse
Regulerte virksomheter som trenger presis og sikker oversettelse av teknisk, medisinsk eller juridisk dokumentasjon, finner en pålitelig partner i AD VERBUM. Med over 25 års erfaring og et proprietært LLM-basert AI-system driftet på EU-servere, kombinerer AD VERBUM teknologisk presisjon med menneskelig fagekspertise i et AI+HUMAN hybrid translation-arbeidsflyt.
AD VERBUM er ISO 27001, ISO 13485 og GDPR-sertifisert, og leverer oversettelse til over 150 språk med full terminologikontroll og null dataeksponering mot offentlige plattformer. Enten du trenger oversettelse av kliniske utprøvingsdokumenter, patentsøknader eller industrielle sikkerhetsmanualene, sikrer AD VERBUMs AI+HUMAN oversettelsestjeneste at hvert dokument møter bransjens strengeste krav til nøyaktighet og compliance.
FAQ
Hva betyr proprietær AI i praksis?
Proprietær AI betyr at utvikleren beholder full kontroll over kildekode, modellparametere og treningsdata, og brukeren får kun tilgang via kontrollerte grensesnitt som API-er. Brukeren kan ikke inspisere eller modifisere modellens interne oppbygning.
Hva er forskjellen mellom proprietær og åpen kildekode AI?
Proprietær AI holder teknologien lukket og leveres som en ferdig tjeneste, mens åpen kildekode AI gjør kode og parametere offentlig tilgjengelig for fri bruk og tilpasning. For regulerte virksomheter gir proprietær AI enklere compliance, men mindre teknisk innsyn.
Hvordan oppfyller proprietær AI GDPR-kravene?
GDPR krever at virksomheter inngår databehandleravtale med leverandøren i henhold til Artikkel 28, og at data ikke brukes til treningsformål. Løsningen må driftes i isolert cloud eller lokalt, og det må foreligge dokumentasjon på behandlingsgrunnlag og revisjonsspor.
Hvilke bransjer bruker proprietær AI mest?
Finanssektoren, helsesektoren og offentlig forvaltning er de mest aktive brukerne av proprietær AI i regulerte sammenhenger, fordi kravene til datasikkerhet, sporbarhet og compliance er absolutte i disse sektorene.
Er proprietær AI tryggere enn åpen kildekode AI?
Proprietær AI er tryggere i regulerte sammenhenger forutsatt at leverandøren tilbyr isolert drift, databehandleravtale og garantier mot gjenbruk av data. Åpen kildekode AI kan være like sikker, men krever at virksomheten selv håndterer all sikkerhet og compliance.
Anbefaling


